It is believed that most of the ORs did not evolve specificity to a single odorant. Rather, a diverse array of such proteins has evolved in order to ensure that practically any odorant will be detected with high probability. Therefore, the olfactory system employs 'probabilistic recognition' [3], in similarity to the immune system. The amino acid residues that form the odorant binding site are therefore expected to be 'hypervariable'. Previous observations [1,4] suggested the presence of such a hypervariable region, encompassing TM domains 3, 4 and 5. We set out to define a better variability profile for OR sequences, and to correlate it with structure and function.
A large number of OR sequences is now available. We performed nucleotide and protein multiple sequence alignment of 167 translatable OR sequences from 9 species. Phylogenetic analysis suggests their classification into at least 20 families (over 40% aa identity). Several pairs of orthologous genes can be discerned, with sequence identities over 95%.
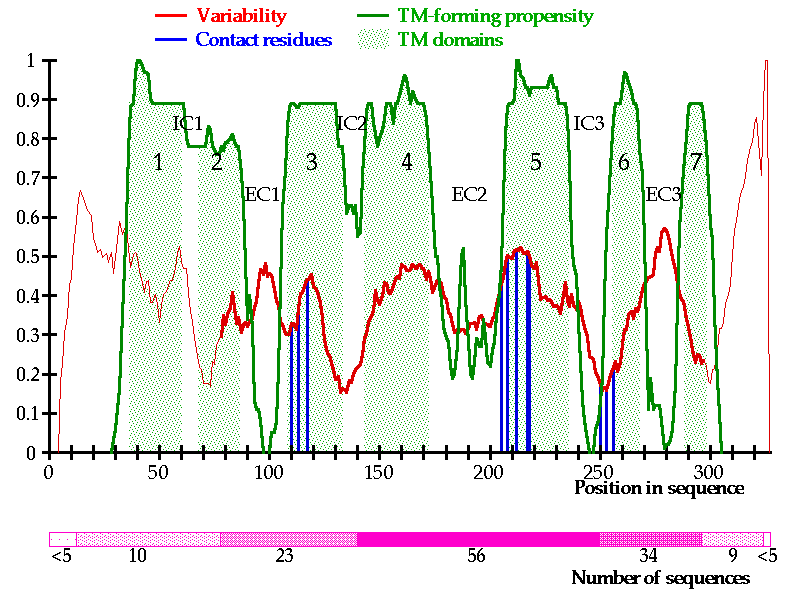
To define the location of the seven TM domains, we used the neural network implemented in the PredictProtein server [5], to calculate the TM-forming propensity for every aminoacid of each sequence. Averaging of these values over columns of the multiple alignment provided very sharp boundaries for the TM domains (see figure). This method integrates information from hydrophobicity, helix-forming propensity and sequence comparison, and provides an improved statistical prediction of the TM regions.
We define a measure of variability V based on Shannon's "information content" as:
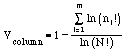 where N is the total number of sequences in an alignment column c, m is the size of the alphabet, and n(i) is the number of occurrences of aminoacid i in the column. Preliminary results show well defined regions with different levels of variability (see figure). Well conserved regions include TM1, TM2, TM7 and the second and third intracellular loops. The most variable regions are the first intracellular loop, the first and the third extracellular loops, and a putative odorant-binding 'barrel' encompassing TM3 to TM5. Fourier analysis of the variability along the entire sequence shows a distinct periodicity of 3.65. This periodicity signal is mapped to some of the predicted TM helices, and cannot be found in the variable extracellular loops. This implies that the variable residues are concentrated on one side of these TM helices, suggesting that they line the odorant-binding pocket and interact with the ligand. Such 'variability moment' can facilitate OR 3D structure modeling by determining the phase of the TMs across the membrane [6,7]. Docking analysis of selected ORs (using rhodopsin-based models) against a database of 70 odorants also suggests that the ligand-contacting residues (see figure) are located within the most variable TM regions of the protein.
where N is the total number of sequences in an alignment column c, m is the size of the alphabet, and n(i) is the number of occurrences of aminoacid i in the column. Preliminary results show well defined regions with different levels of variability (see figure). Well conserved regions include TM1, TM2, TM7 and the second and third intracellular loops. The most variable regions are the first intracellular loop, the first and the third extracellular loops, and a putative odorant-binding 'barrel' encompassing TM3 to TM5. Fourier analysis of the variability along the entire sequence shows a distinct periodicity of 3.65. This periodicity signal is mapped to some of the predicted TM helices, and cannot be found in the variable extracellular loops. This implies that the variable residues are concentrated on one side of these TM helices, suggesting that they line the odorant-binding pocket and interact with the ligand. Such 'variability moment' can facilitate OR 3D structure modeling by determining the phase of the TMs across the membrane [6,7]. Docking analysis of selected ORs (using rhodopsin-based models) against a database of 70 odorants also suggests that the ligand-contacting residues (see figure) are located within the most variable TM regions of the protein.