


A Model For Discovering 'Containment' Relations
Shimon Ullman, Nimrod Dorfman, Daniel Harari

Abstract
Rapid developments in the fields of learning and object recognition have been obtained by successfully developing and using methods for learning from a large number of labeled image examples. However, such current methods cannot explain infants' learning of new concepts based on their visual experience, in particular, the ability to learn complex concepts without external guidance, as well as the natural order in which related concepts are acquired. A remarkable example of early visual learning is the category of 'containers' and the notion of 'containment'. Surprisingly, this is one of the earliest spatial relations to be learned, starting already around 3 month of age, and preceding other common relations (e.g., 'support', 'in-between'). In this work we present a model, which explains infants' capacity of learning 'containment' and related concepts by 'just looking', together with their empirical development trajectory. Learning occurs in the model fast and without external guidance, relying only on perceptual processes that are present in the first months of life. Instead of labeled training examples, the system provides its own internal supervision to guide the learning process. We show how the detection of so-called 'paradoxical occlusion' provides natural internal supervision, which guides the system to gradually acquire a range of useful containment-related concepts. Similar mechanisms of using implicit internal supervision can have broad application in other cognitive domains as well as artificial intelligent systems, because they alleviate the need for supplying extensive external supervision, and because they can guide the learning process to extract concepts that are meaningful to the observer, even if they are not by themselves obvious, or salient in the input.
Keywords: Containment relation; Spatial relations learning; Infants' perceptual learning; Developmental trajectory; Unsupervised learning; Computational model.
Introduction
In the first months of life infants acquire significant knowledge about the world, which allows them to form expectations about their environment, and guide their interactions with their surroundings. A major aspect of this knowledge is recognizing objects and their interactions. An essential and extensively studied component of this capability is forming categories of spatial relations between objects, such as occlusion (A is behind B), support (A is on B) and containment (A is inside B).
In the current work we describe a computational model that learns about 'containment', one of the earliest spatial relations to be learned, and a range of related notions, such as 'support' and 'cover'. This learning is obtained in the model fast and without supervision, relying only on perceptual processes that are present in the first months of life.
Studies of infants' ability to recognize and categorize spatial relations between objects have shown that selective responses to containment events emerge as early as about 2.5 months of age, and continue to develop through a characteristic sequence of stages. The two main goals of the model are to provide an explanation for infants' ability to learn complex concepts such as containment early and without guidance, as well as the natural order of concepts acquisition. The ability to learn complex concepts visually in an unguided manner goes beyond current highly successful computational models, which learn in a supervised manner, using large data sets of supplied labeled examples. In contrast, the current model is able to acquire the visual concept of 'containment' and related relations by 'merely looking', and it naturally goes through stages in the observed developmental trajectory. It recognizes first dynamic occlusion events, and then generalizes to static images (Figure 1). It distinguishes between 'behind', 'in-front' and 'inside' relations, and can tell apart 'tight' and 'loose' fit. Learning 'support' relations is more difficult in the model and emerges only later. The model deals with related concepts (e.g. 'cover' and predicts developmental steps that can be tested empirically.
The model
Paradoxical occlusion as a teaching cue
How can relatively complex and abstract concepts related to containment be learned without guidance, by being visually exposed to relevant containment events?
We suggest that the learning of containment and related relations is guided internally by teaching signals, which are present already at the onset of the learning process. As shown by the model, in both dynamic and static visual input, containment can be identified as an instance of 'paradoxical occlusion', defined as a situation where an object O, which occludes a second object C, is at the same time also occluded by C. Typically, an occlusion relation between two objects goes in one direction: one object either occludes, or being occluded by, the second object. This simple ordering is violated in a paradoxical occlusion situation. It is known that during early visual experience infants develop the ability to segregate a scene into distinct objects, and determine occlusion relations between them. Our model suggests that the occurrence of an unusual paradoxical occlusion event is noted by the system and serves as an early internal signal for containment configurations, which then get elaborated by additional learning. The model demonstrates that paradoxical occlusion serves as an efficient and reliable internal guidance, which leads to the learning of containment and related notions in a human-like manner, and based on similar initial capacities.
Capacities of the model
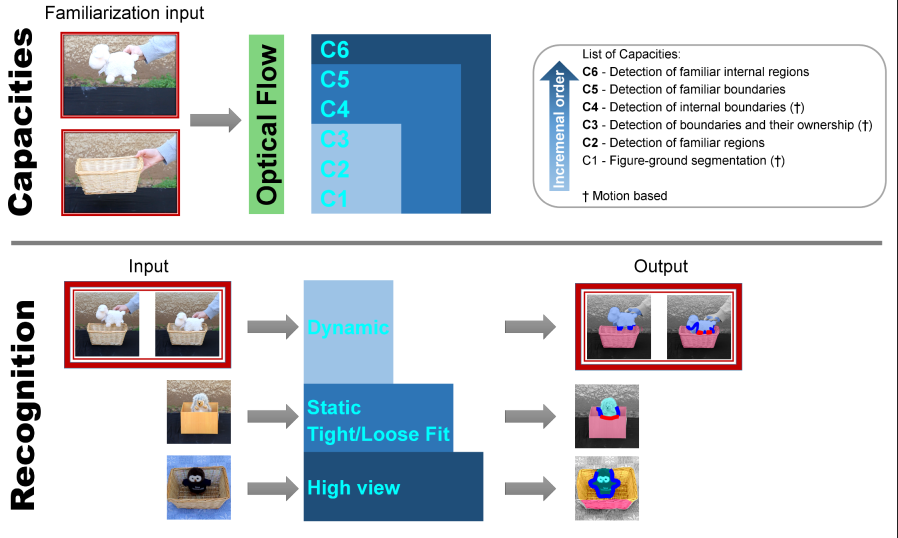
The model includes a number of perceptual capacities, which are assumed to develop over time in the visual system at an early age, and support the acquisition of containment concepts. These capacities are listed as C1-C6 below, to make explicit what are the assumptions built into the model. As can be seen, they are all processes dealing with object segregation and boundary detection, starting from moving objects and generalizing to static scenes. The different capacities are listed briefly, together with the empirical evidence supporting their role in the visual system at an early age, when containment concepts are acquired.

Capacity C1: Figure-ground segmentation of moving regions. When a region in the image moves against a stationary background, it is separated from the background based on its motion, and the model constructs and stores a simple representation of the region, based on low-level features included in the region.
Capacity C2: Detection of familiar regions in a static scene. Based on the representation obtained in capacity C1, the model can detect a familiar region and separate it from its background in a static scene.
Capacity C3: Detection of boundaries and their ownership at motion discontinuities. The model detects object boundaries of a moving region by identifying motion discontinuities, and determines 'ownership' direction of the boundary (which side belongs to the object). The model extends the representation of the moving region to include the ownership along its boundaries.
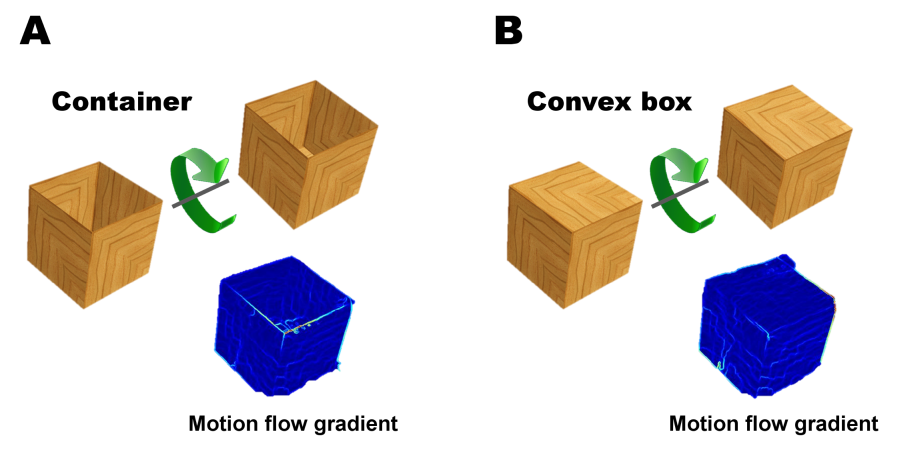
Capacity C4: Detection of internal boundaries of a moving region. The boundaries detected in capacity C3 are the bounding contours, separating the moving object from the background. This is extended next to the detection of motion discontinuities within the region of an object, as internal boundaries. Such internal boundaries are typically produced at a container's rim. The motion signal is weaker at these internal boundaries compared with the external ones (because the motion difference across the boundary is small), and therefore the model includes them as a later stage. The model represents the internal boundary as a part of the object.
Capacity C5: Detection of familiar boundaries in a static scene. The detection of external and internal object boundaries is based originally on motion discontinuities. Based on the representation in capacities C3, C4, external and internal boundaries of objects can subsequently be detected in a static scene, starting with familiar objects, or familiar simple shapes, and gradually generalizing to novel ones. The extraction of boundaries, as well as segmentation and occlusion in general, appear earlier in development for familiar objects, and later generalize to novel objects. In terms of the containment model, we focus on the stage of familiar objects, but when the generalizations above take place, they will also naturally allow the containment model to generalize to novel objects.
Capacity C6: Detection of familiar internal regions in a static scene. In a container, based on capacities C2-C5, the model can discriminate between the 'front' and 'back' sides of the internal boundary. The external bounding boundary of an object, detected in capacity C3 above, separates the object as a whole from its background. In a similar manner, an internal boundary divides the object region into two sub-regions, separated by the boundary. The 'front' side is the region owning the internal boundary.
Stages of recognition
The model develops to gradually acquire notions related to containment and containers. The following description is divided into a sequence of stages, which make explicit the cues and capacities used by the model to acquire the relevant notions without requiring external guidance.
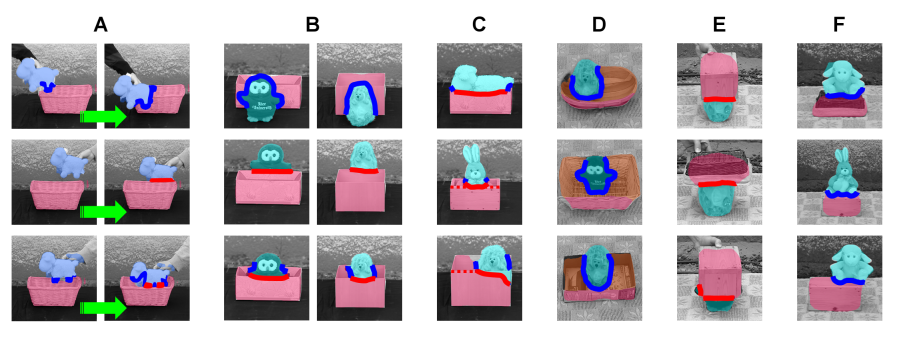
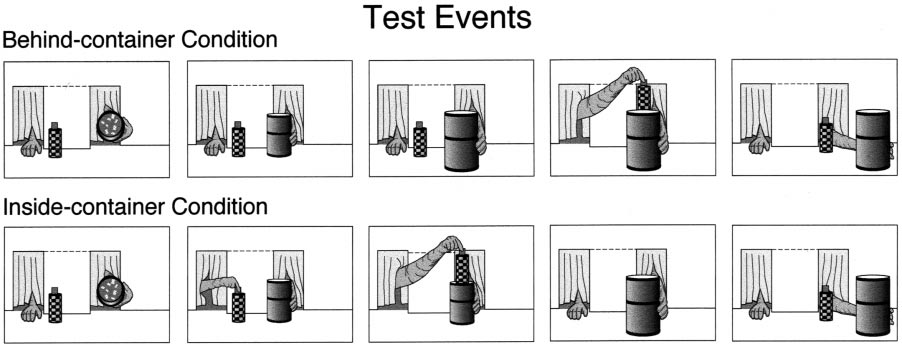
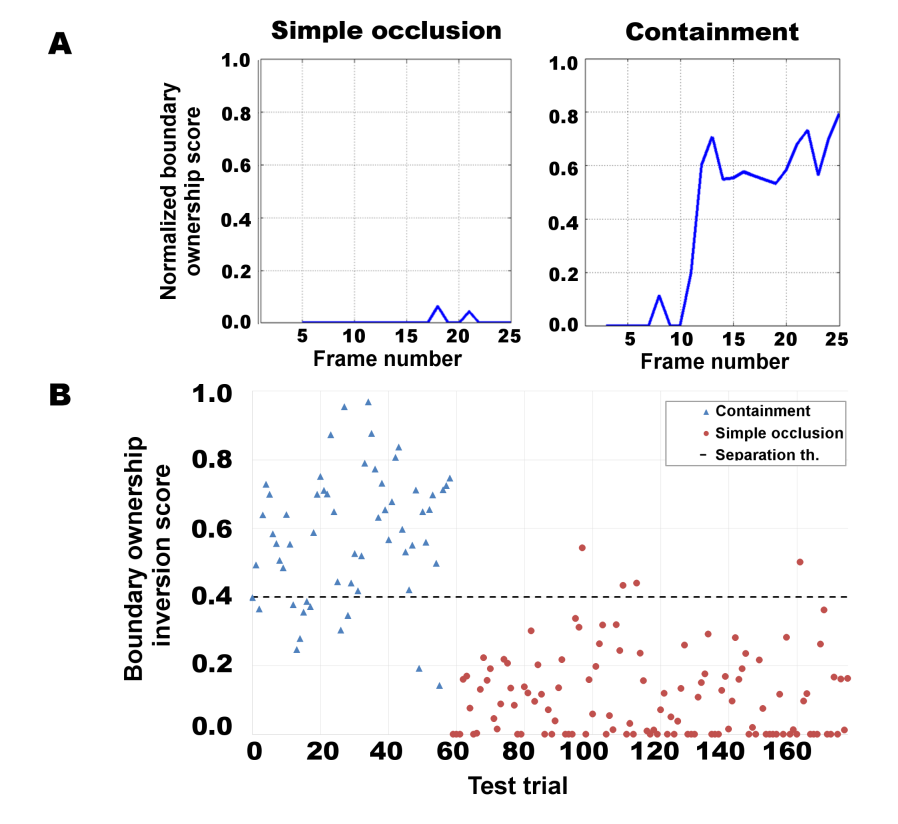
Recognizing dynamic containment. The model's initial and simplest recognition stage of containment relations between objects (as well as 'in-front', 'behind'), relies on motion information in dynamic displays, presented during training and testing. These dynamic displays are similar to dynamic scenarios used in studies of the earliest specific responses to containment relations in infants. Under these conditions, the model is first presented with brief familiarization video sequences of moving objects (both containers and non-containers), from which it learns to detect the objects' regions in subsequent test videos, even when one of them (e.g., the container) is stationary (capacities C1, C2). Following familiarization, the model is presented with dynamic containment and occlusion events: an object is being moved by hand, to be placed in-front, behind, or inside a container. In such a dynamic sequence, when an object O is inserted into a container C, at the moment when a 'containment event' takes place (entering a cavity in the container C), object O turns from progressively occluding C to become partly occluded by C, signaling a paradoxical occlusion, which is specific to containment relations. This event is detected by a switch in boundary ownership (capacity C3), from being owned by the moving object to the stationary container. When this switch occurs inside region C rather than at its boundary, it identifies unambiguously the container C and the contained object O. In a 'behind' relation, the occlusion relation does not switch: C consistently occludes O (the boundary between them is owned by C). Similarly, in an 'in-front' relation, the occlusion relation also does not switch, and the boundary is consistently owned by the moving object O.
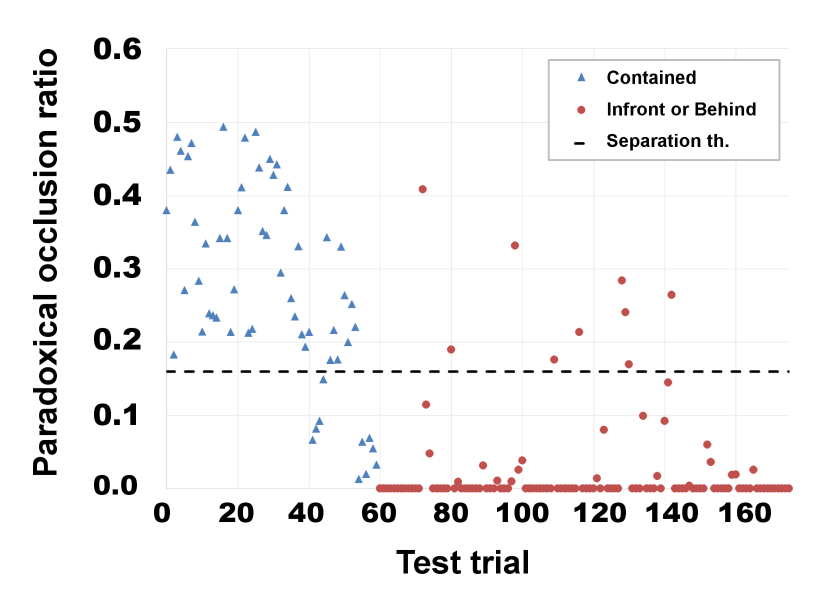
Recognizing static containment. The next stage in the model is the ability to recognize containment relations (as well as 'in-front' and 'behind') not only in dynamic events, but also in static scenes. The extension that makes this possible is the ability to recognize external and internal object boundaries in stationary scenes. Object boundaries are learned originally from motion discontinuities. They include the external object boundaries, and, for a container, also an internal boundary γ (at the container's rim), which is a characteristic part of a container (capacities C3, C4). The main addition to the model, listed as capacity C5 above, is the ability to recognize, in a static image, the boundaries of objects observed during a familiarization stage, together with their boundary ownership (the boundary side belonging to the object). The boundary between objects specifies their occlusion relations: the object that owns the boundary occludes the object on the other side. In a static scene, paradoxical occlusion is signaled not by a dynamic switch in boundary ownership, but by conflicting occlusion relations between the two objects. The conflicting cues arise along different parts of the common boundary between the container C and the inserted object O. A part of the common boundary is owned by the object O, and another part, along C's internal boundary, is owned by the container C. Similar to the dynamic case, the container C both occludes and is being occluded by O, signaling a 'containment' relation. Similar to the model, infants are sensitive to the internal boundary at the rim of a container. When the back of a box is removed, transforming the internal boundary between the front and back of the box from an internal to external boundary, infants no longer interpret the box as a container, but rather as an occluder. The relation of in-front / behind between image regions induces at this stage three types of relations between an object and a container: object in-front, object behind, and paradoxical occlusion. The empirical evidence shows that at about the same time, these classes of object relations become associated with predictions about an expected object location, in the following way. When an object is placed behind a container, a motion of the container will reveal the occluded object. In contrast, when the relation is a paradoxical occlusion, a motion of the container will transport the object with it. Infants were shown to look longer at 'surprising' events, when these predictions are violated; for example, when an object is inserted into a container, but then becomes revealed when the container moves, rather than being transported with it. This use of the different spatial relations to predict outcomes such as 'reveal' or 'transport' caused by the container motion, is an early example of associating meaning with the newly formed categories of spatial relations, similar to the notion of 'Quinian bootstrapping' in concept learning.
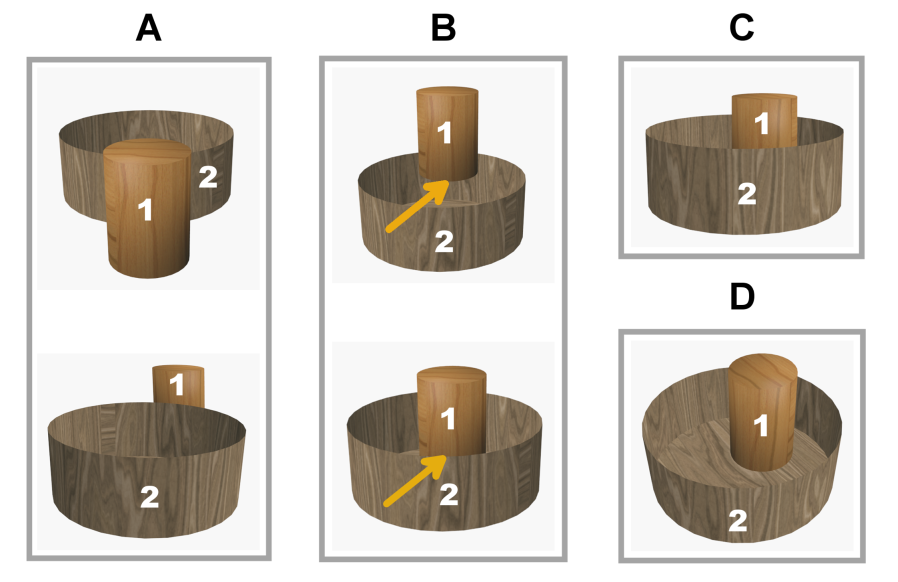
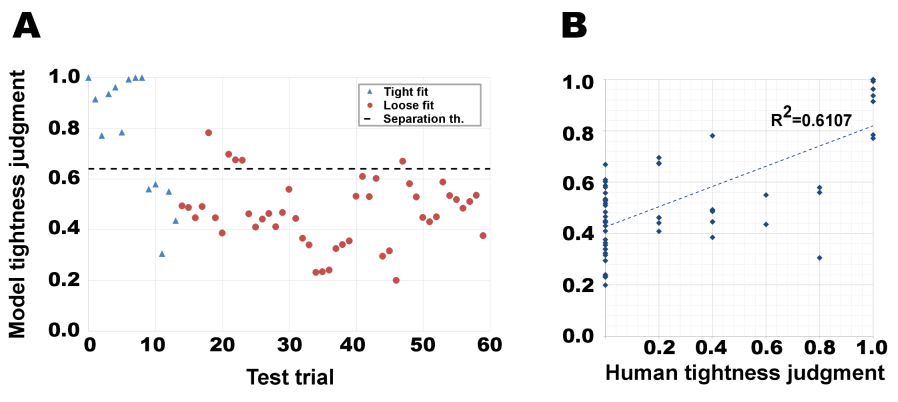
'Tight' versus 'loose' fit. A distinction that follows in the model is between 'tight' and 'loose' containment relations, which infants are sensitive to. In a containment event, an object O can either fit tightly inside a container C, or it may occupy only a part of C's cavity, and may be free to move within it. Discrimination between tight and loose static containment is based in the model on the internal boundary of the container (capacities C4, C5) and the object regions on its two sides (capacity C2), extracted automatically during the familiarization stage. The model produces a measure of the containment 'tightness' based on the proportion between the total length of C's internal boundary, and the length of the common part of the internal boundary, shared between C and the inserted object O: containment is tight if β, the boundary between the object and container, and the rim γ are similar in size, and loose if β is significantly smaller. This stage depends, therefore, on the reliable detection of C's internal boundary through most of its length. In analogy with the model, infants develop sensitivity to the relative width of the inserted object compared with the container cavity width at about 4 months, and it is higher at this age than their sensitivity to height comparisons. Interestingly, the difference between width and height judgments appears to persist in some form into adulthood, and can be detected under challenging conditions, where occluded or contained objects slightly change their width or height, while invisible during a dynamic occlusion or containment event.
Recognizing static containment from a high view angle. High-angle containment is more difficult in the model than a low-view configuration, because the object O is no longer adjacent to the internal boundary γ, and is not occluded by the container. Therefore, an additional capacity is required for this configuration. In the model, high-view containment is identified by using the internal boundary to divide the container region into sub-regions (capacity C6). In the early stage, an object in the image is represented by a single region, (capacities C1-C4). Subsequently, internal object boundaries are detected (capacities C4, C5). The addition of an internal boundary naturally breaks the single object region into two regions joined along the internal boundary. For dealing with high-view angle, the model uses the natural representation of the two sub-regions, 'front' and 'back' of a container, capacity C6 above (simple objects, without an internal discontinuity, are still represented by a single region). High view containment is detected when all the common borders between O and C are owned by O, and separate O from the 'back' region of C. In the refined representation, instead of a single region, the container is now composed of two regions, separated by the internal boundary. In this representation, the object can be in-front of the container in different ways: it can be in front of the container's Front region only, Back region only, or both. One of these, when the object is in front of the Back region only, naturally corresponds to high-view containment. In the model, the relation of high-view containment will be confused initially with in-front relation (which is in fact correct as well, since the object lies in front of the container's regions behind it). Connecting this new high-view configuration to 'containment' requires in the model an additional learning stage, which can be supported in two ways. First, the high-view and low-view containment configurations are similar in terms of boundary ownerships along the object-container common border, and one can transform to the other with a small change in the observer's view direction. Second, similar to low-view, a motion of the container in high-view will transport the object with it. Learning to predict the object motion, which infants are sensitive to, will therefore result in treating low-view and high-view containment in a similar manner. The model's prediction that high-view containment comes at a later stage than low-view is consistent with the known data. However, since high-view containment has not been tested in the past at ages as early as low-view, the prediction remains to be tested more fully in future studies.
Extensions to related concepts: support and cover relations. In the model, the 'support' ('on-top') relation is more difficult than containment since the discontinuity boundary γ, present in containers, is replaced in this case by a convex object edge. Our simulations show that an extended capacity is required for detecting this boundary. Briefly, the surface boundaries of a supporting object have no depth discontinuity (only a discontinuity in surface orientation), making them significantly more difficult to detect by motion discontinuities. The model suggests that the acquisition of 'support' relation is delayed relative to 'containment', because its learning depends on the reliable detection of the convex internal boundary. A cover relation is similar to containment (in both, object O is partially inserted into a cavity in C), and can therefore be learned in a similar manner. However, this learning in the model will depend crucially on whether the internal discontinuity γ at the covering object's opening rim, is made visible during familiarization, since this discontinuity is required for perceiving the hollow cavity of the covering object. The model predicts that low-view 'containment', high-view, and 'support' will be acquired in this order, and that 'cover' will be learned spontaneously, provided that the rim γ will be visible during familiarization, but will not be learned otherwise at this stage. The prediction can be tested empirically, by a small but crucial modification to experiments conducted by, which showed that infants are able to recognize covering events already at 2.5 months. We predict that a similar experiment, but without a dynamic presentation showing the rim of the covering object at the beginning of the trial, will fail to demonstrate a consistent distinction between 'cover' and 'in-front' relations.
Experimental evaluation
Our model uses evolving capacities to make increasingly complex judgments about containment relationships. To demonstrate and evaluate the model's recognition capabilities at the different stages, we used a set of natural videos and images showing containers and simple objects at multiple spatial relations. The representations in the model are learned automatically and without supervision by introducing the objects to the model using unlabeled familiarization video sequences. We demonstrate how the learned representations can be used to perform complex judgments about containment relations including discriminating between container and non-container (simple) objects, and classifying occlusion relations including 'in-front', 'behind' and 'inside'.

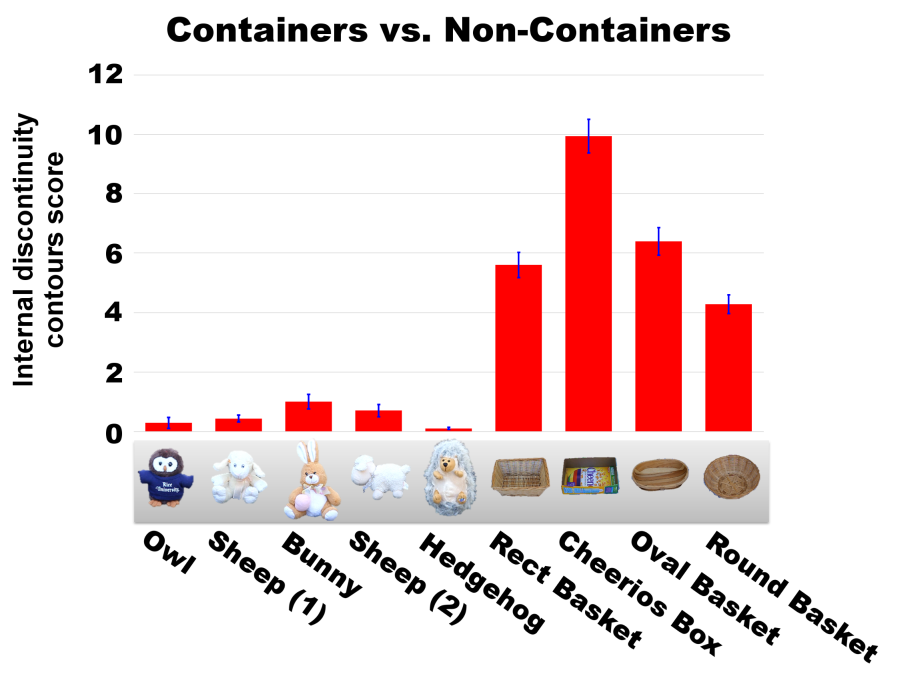
Containers vs. non-containers
Recognizing containment in dynamic scenes
Recognizing containment in static scenes at a low-view
Tight vs. loose fit
Extensions to related concepts: support and cover relations
Discussion
Concepts related to spatial relations in general and containment in particular are a fundamental component of human cognition, and they play a useful role in reasoning about a broad range of physical phenomena. Their acquisition in early development raises a number of basic questions: how can they be acquired early and without supervision? why is containment, which computationally appears abstract and complex, acquired before other relations, and what causes the particular time trajectory of its acquisition? The current model shows how containment concepts can emerge early and without explicit supervision, and in a predictable order. The main mechanism that allows this learning is the detection of paradoxical occlusion, and its use for guiding the learning process. The ability to detect and pay attention to paradoxical occlusion can be expected in early developmental stages, when infants rapidly learn to detect object boundaries and establish occlusion relations. The paradoxical occlusion signal then provides internal implicit supervision, and guides the system to acquire gradually a range of useful containment-related concepts.
The model makes predictions about the acquisition order (on high-view and cover), which could be tested in future studies. High-view containment categorization comes later than low-view in the development of containment relations (around 6 months). In the model, this requires an extension of occlusion detection from paradoxical occlusion to the configuration of occluding an object's back part. The model suggests that at an early age (prior to capacity C4), high-view containment should be confusable with an in-front relation (since the object occludes the container, before a distinction into 'front' and 'back' regions is made). With respect to cover, the model predicts that a small change in the stimuli presentations used in the past will lead to an inability to distinguish 'cover' from 'in-front' relations.
At an early stage (prior to capacity C6), when the container is represented in the model as a solid region rather than a set of separable front and back regions, the sensitivity to paradoxical occlusion incorporated in the model, may be a special case of violating an expectation, since unlike simple occlusion, in paradoxical occlusion two opposing occlusion relations exist between the same two objects. Consistent with general developmental processes, this unexpected configuration can enhance the learning of containment relations and their implications.
Detecting static paradoxical occlusion may be aided by depth information, which was not used by the current model. However, binocular vision and pictorial depth perception evolve gradually starting at a few months of age, and their contribution to early stages of containment learning is likely to be limited. The model focuses on early stages of learning to identify containers and containment; reaching a comprehensive understanding of concepts related to 'containment' at an adult level is likely to develop over an extended period, and to incorporate non-visual components, including sensory-motor manipulation.
At a general level, the model uses internal implicit supervision to guide the learning process, unlike external guidance by labeled training examples. A similar strategy of using simple internal signals, typically motion based, and consistent with infants' early capacities, have been proposed for several other learning tasks, which appear at a surprisingly early age, including general object segregation, and the recognition of hands and direction of gaze. Biologically, the automatic use of specific teaching signals to guide learning may be based on an appropriate pre-existing general patterns of connectivity between cortical regions which gradually develop to acquire specific functional specializations. For example, in the containment case, the models suggests a pattern of connectivity between regions dealing with segregation and ordinal depth, to regions involved with objects and their properties, such as the ability to predict the location of hidden object behind or inside containers.
The mechanism of using internal implicit supervision to guide learning is likely to have broader application in other cognitive domains, because it serves two highly useful and general roles. First, it alleviates the need for supplying extensive external supervision, and second, it can guide the learning process to extract concepts that are meaningful to the observer, even if they are not by themselves highly salient in the visual input. Such aspects of cognitive learning discovered in infants can conceivably be adapted for use by future machine learning systems, which currently often rely on large annotated data sets supplying external supervision, and focus on image structures that are statistically salient.
In the current model, the internal guiding signals were incorporated in the model prior to the learning stage. An intriguing alternative for future studies is to develop more extended learning methods, which cover both evolutionary and individual aspects. Such a process would use prolonged unsupervised training to discover on their own useful guiding signals, which can subsequently support fast unsupervised learning from experience.
Paper
Ullman, S., Dorfman, N. and Harari, D. (2019). A model for discovering 'containment' relations. Cognition, 183, 67-81. (Online).
Acknowledgements
The work was supported by European Research Council (ERC) Advanced Grant "Digital Baby", Israeli Science Foundation (ISF) grant 320/16 and the German Research Foundation (DFG Grant ZO 349/1-1).
Author contributions
S.U., N.D. and D.H. contributed equally to this work.