


Extending Recognition in a Changing Environment
Daniel Harari and Shimon Ullman
Abstract
We consider the task of visual recognition of objects and their parts in a dynamic environment, where the appearances, as well as the relative positions between parts, change over time. We start with a model of an object class learned from a limited set of view directions (such as side views of cars or airplanes). The algorithm is then given a video input which contains the object moving and changing its viewing direction. Our aim is to reliably detect the object as it changes beyond its known views, and use the dynamically changing views to extend the initial object model. To achieve this goal, we construct an object model at each time instant by combining two sources: consistency with the measured optical flow, together with similarity to the object model at an earlier time. We introduce a simple new way of updating the object model dynamically by combining approximate nearest neighbors search with kernel density estimation. Unlike tracking-by-detection methods that focus on tracking a specific object over time, we demonstrate how the proposed method can be used for learning, by extending the initial generic object model to cope with novel viewing directions, without further supervision. The results show that the adaptive combination of the initial model with even a single video sequence already provides useful generalization of the class model to novel views.
Keywords: part-based visual object recognition, adaptive part detection, unsupervised learning, learning from motion, spatio-temporal model, probabilistic graphical model, generative model.
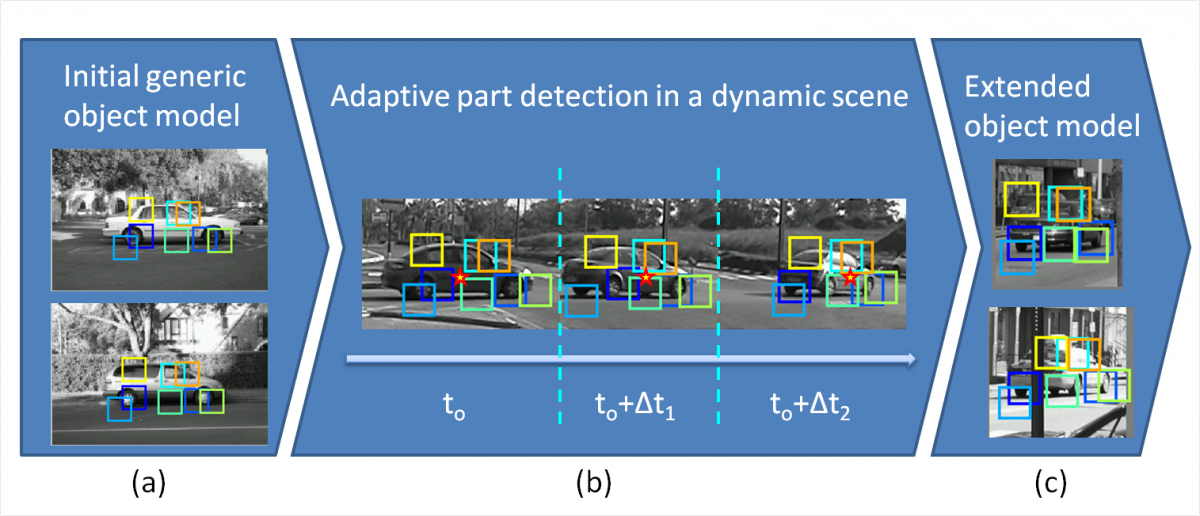
Model Overview
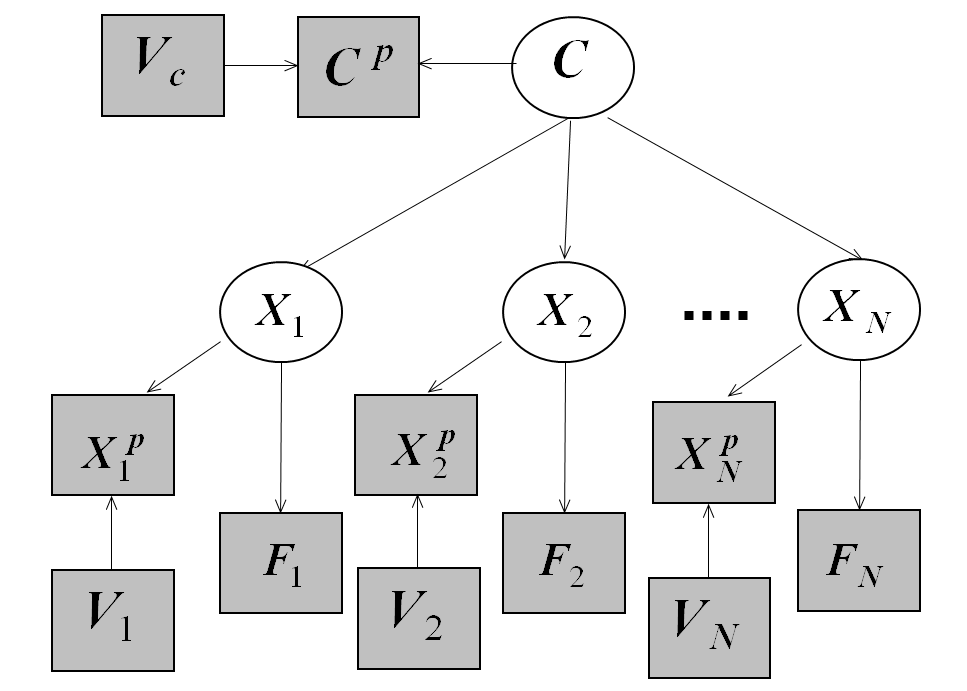
Our adaptive model is initially a static, single-image parts detection model of an object class (such as cars or airplanes), with a star-like geometric structure. This model is learned from a limited set of view directions (such as side views). When applied to video sequences, the model acts as a standard static classifier on each frame until an instance of the object class is successfully detected at frame t0. The model is then applied to every two consecutive image frames t and (t+Δt) of the video sequence, as long as the object is reliably detected. Parts interpretation (identity and location) at time (t+Δt) is obtained by combining two sources: the model M(t) at time t, and the optical flow between the frames. The model is then updated to M(t+Δt) to be used in the subsequent frame. The updated model at each frame is an adapted instance of the initial model, based on the two corresponding views. We utilize adaptive approximate nearest neighbors (ANN) search, combined with statistical kernel density estimation (KDE), for efficient online updating of the model, using the dynamically changing views to extend the initial object model as described below.
Adaptive Part Detection
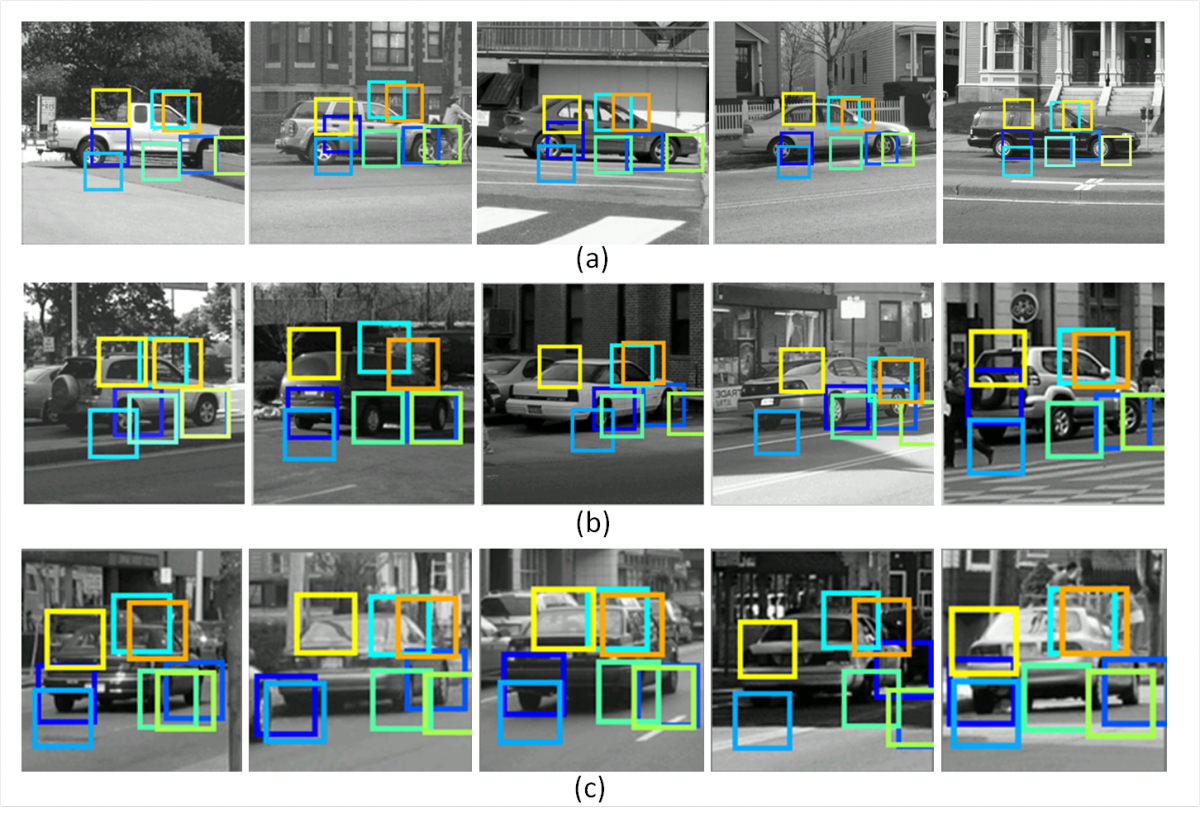
Our algorithm first detects an object class instance in the video input based on its initial static model. Once the object is reliably detected by the initial model, our model is applied to every two consecutive frames of the input video sequence, while adapting to the dynamic changes in viewing directions of the object and its parts. Our online update algorithm is gradual in the sense that the adapted model combines the old and current parts appearances and object geometries. The mixture is obtained by adding the appearance and displacement from the current model to the ANN structure.
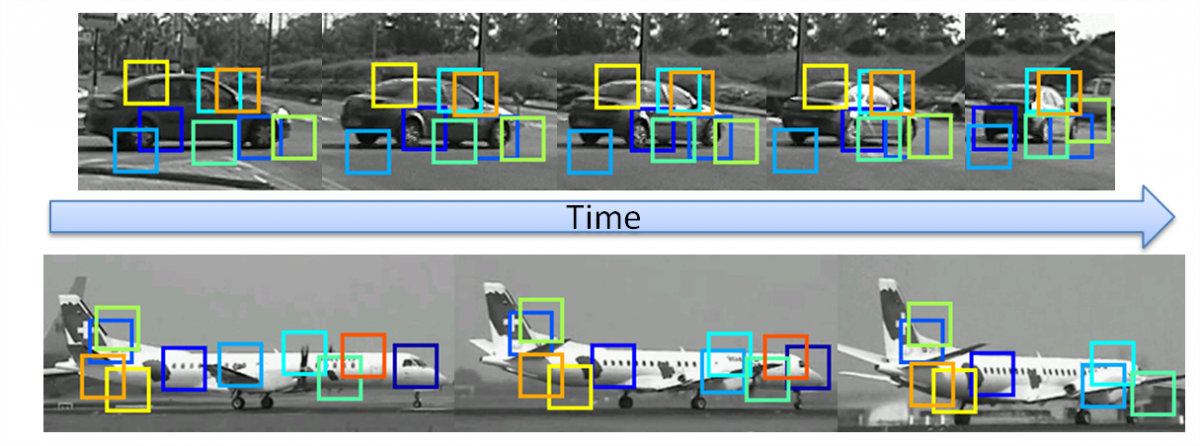
We compared this mixed adaptation with an alternative where the current-frame model (appearance and geometry of the detected object) completely replaces the previous model. The evaluation for the detection performance of the object and parts was done on a car video sequence. Our adaptive algorithm yielded 70% AP for the detection of the whole object and 60% AP for the detection of the individual parts. The replacement alternative yielded 58% AP for the detection of the whole object, but only 40% AP for the detection of the parts, which is similar to the performance of the initial static model of 44% AP for the object detection and 39% AP for the parts detection. These results demonstrates the benefit of using a mixture of the initial model with the novel input, even in dealing with views not included in the original model.
Learning New Views
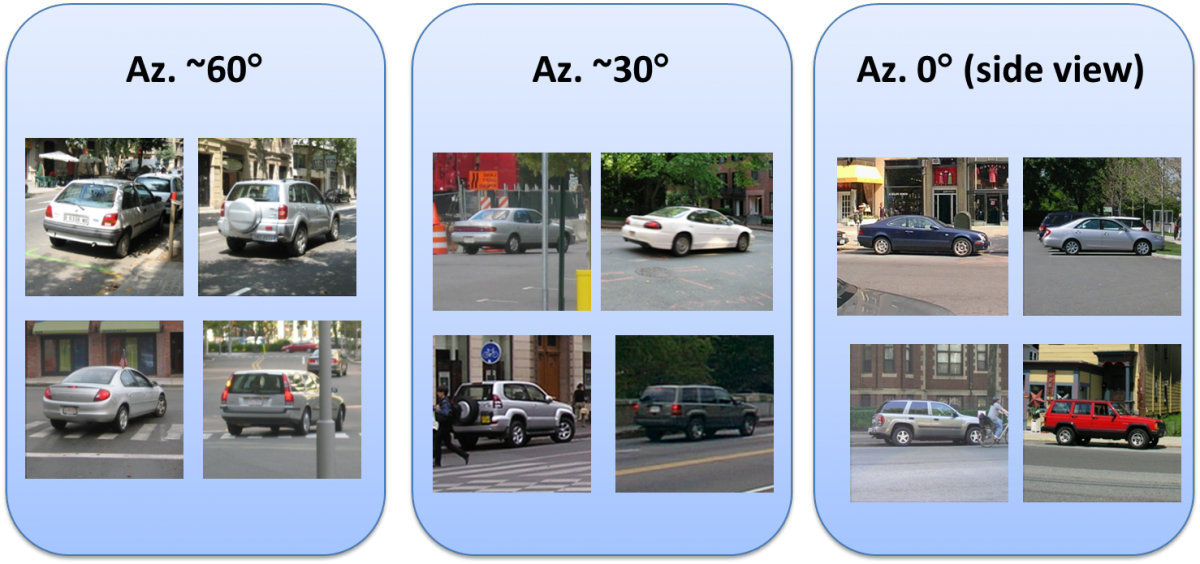
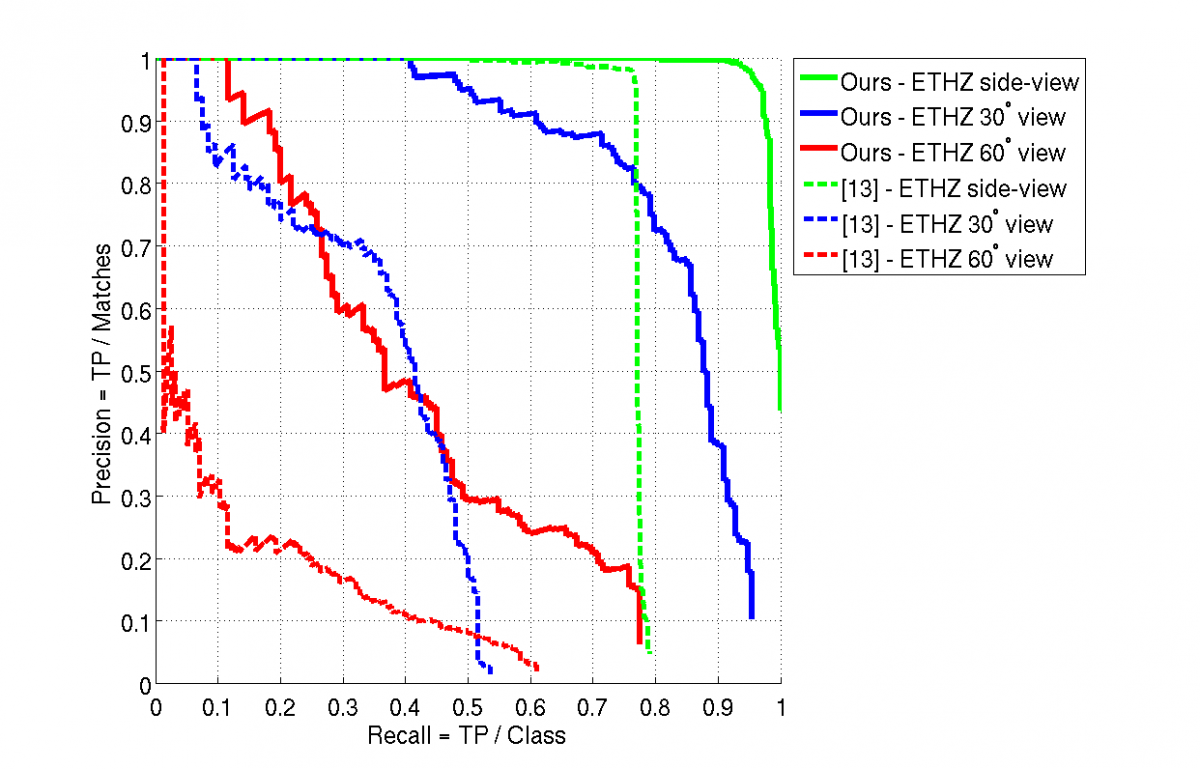
Our algorithm, when applied to dynamic visual input, adapts to changes in viewing directions of the object and extends the initial model to cope with novel views of the class object. In this experiment we show that the adaptive combination of the initial model with even a single video sequence already provides useful generalization of the class model to novel views. To evaluate the detection performance of the updated model, we tested the car model that was adapted to a turning car, on a set of car images seen from 3 different views: a side-view, roughly 30° view and about 60° view (Cornelis et al., 2006). Each image contains a different car instance, none of which was already observed by the model (neither during the training of the initial model, nor in the video sequences). For comparison, we also tested a state-of-the-art object detector by (Felzenszwalb et al., 2010), that was trained on side-view car images. The results in following graph show that the updated model generalizes to the new viewing directions of 30° and 60° without losing the performance on the initial side-view.
Paper
D. Harari and S. Ullman (2013). Extending Recognition in a Changing Environment. Proceedings of the International Conference on Computer Vision Theory and Applications - VISAPP, 1: 632-640. (Abstract, PDF)