
-
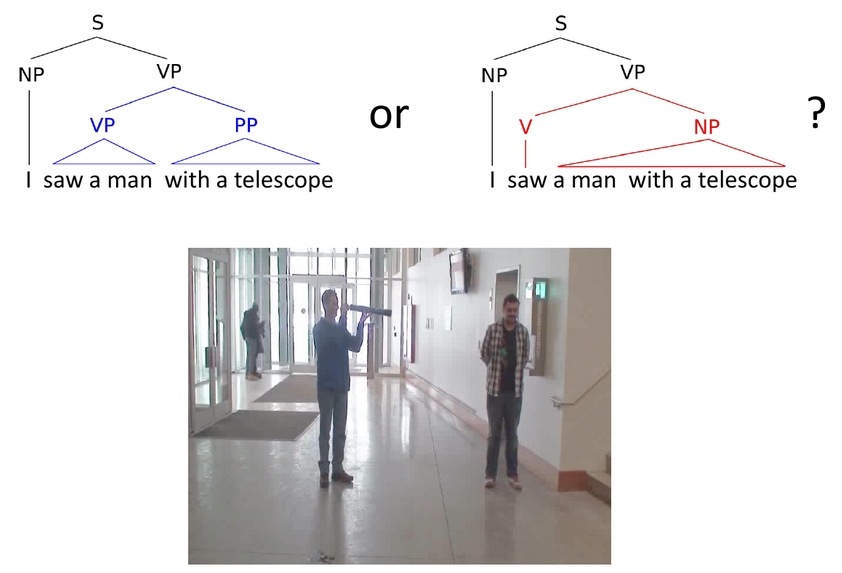 Do you see what I mean? Visual resolution of linguistic ambiguities
Do you see what I mean? Visual resolution of linguistic ambiguitiesUnderstanding language goes hand in hand with the ability to integrate complex contextual information obtained via perception. In this work, we present a novel task for grounded language understanding: disambiguating a sentence given a visualscene which depicts one of the possible interpretations of that sentence. To thisend, we introduce a new multimodal corpus containing ambiguous sentences, representing a wide range of syntactic, semantic and discourse ambiguities, coupled with videos that visualize the different interpretations for each sentence. We address this task by extending a vision model, which determines if a sentence is depicted by a video. We demonstrate how such a model can be adjusted to recognize different interpretations of the same underlying sentence, allowing to disambiguate sentences in a unified fashion across the different ambiguity types.
-
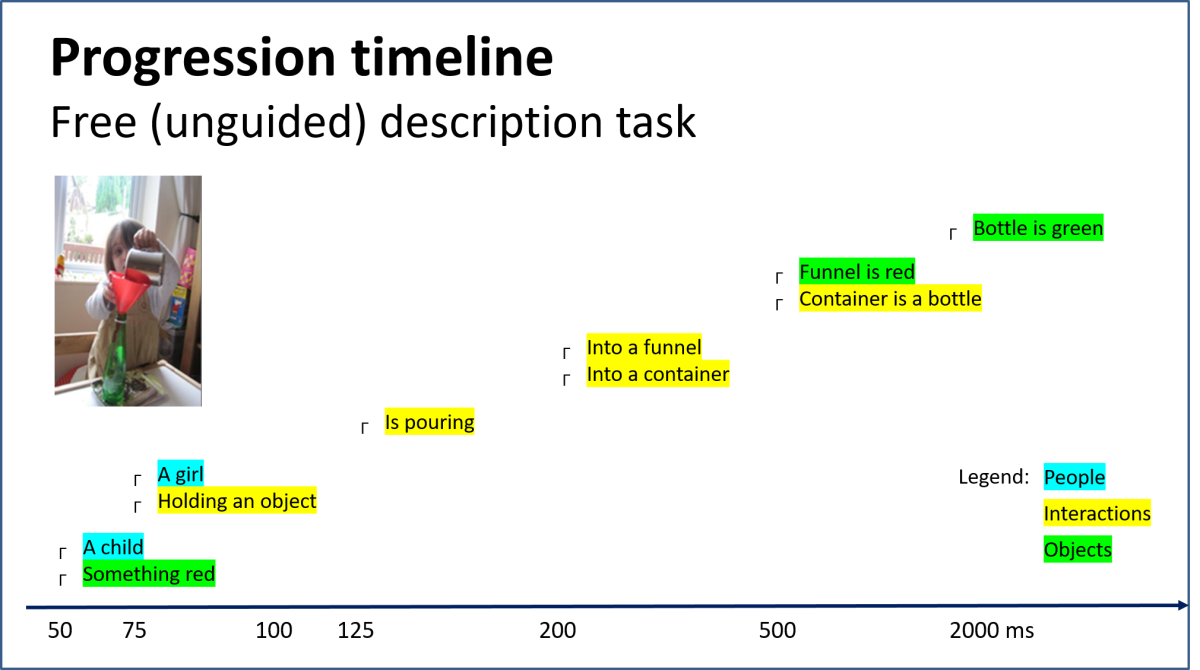 The dynamics of scene understanding
The dynamics of scene understandingVisual scene understanding involves processing and integration from different levels of visual tasks, including recognition of objects, actions and interactions. This study focuses on the dynamics of scene understanding over time and in particular, on the time trajectory of scene interpretation, by controlling the exposure time. We collected detailed descriptions from human participants (MTurk) to stimuli images portraying various interactions between animate agents (humans and pets) and other agents and objects, focusing on the type of objects and agents in the image with their properties and inter-relations. Stimuli images were presented at seven exposure conditions between 50 to 2000ms followed by a mask. Preliminary results indicate consistent trends in the time evolution of scene perception: (i) human agents are reported earlier than objects and global scene description, even when objects appear at the center of fixation (e.g. ‘two men’ before ‘a park bench’); (ii) actions are reported earlier than the acted upon objects (e.g. ‘drinking’ before ‘cup’); (iii) for human agents, the number of agents is reported early, followed by age, and gender is reported on the average later (e.g. ‘two people’, before ‘two kids’, and then ‘two boys’). These findings are interesting from a modeling perspective since they do not fit the common scene understanding paradigm in computer vision, where objects are first detected and only then their inter-relations are processed.

Computer Vision and Visual Intelligence
