
-
 Measuring and modeling the perception of natural and unconstrained gaze in humans and machines
Measuring and modeling the perception of natural and unconstrained gaze in humans and machinesHumans are remarkably adept at interpreting the gaze direction of other individuals in their surroundings. This skill is at the core of the ability to engage in joint visual attention, which is essential for establishing social interactions. How accurate are humans in determining the gaze direction of others in lifelike scenes, when they can move their heads and eyes freely, and what are the sources of information for the underlying perceptual processes? These questions pose a challenge from both empirical and computational perspectives, due to the complexity of the visual input in real-life situations. Here we measure empirically human accuracy in perceiving the gaze direction of others in lifelike scenes, and study computationally the sources of information and representations underlying this cognitive capacity. We show that humans perform better in face-to-face conditions compared with ‘recorded’ conditions, and that this advantage is not due to the availability of input dynamics. We further show that humans are still performing well when only the eyes-region is visible, rather than the whole face. We develop a computational model, which replicates the pattern of human performance, including the finding that the eyes-region contains on its own, the required information for estimating both head orientation and direction of gaze. Consistent with neurophysiological findings on task-specific “face” regions in the brain, the learned computational representations reproduce perceptual effects such as the ‘Wollaston illusion’, when trained to estimate direction of gaze, but not when trained to recognize objects or faces.
-
 Discovery and usage of joint attention in images
Discovery and usage of joint attention in imagesJoint visual attention is characterized by two or more individuals looking at a common target at the same time. The ability to identify joint attention in scenes, the people involved, and their common target, is fundamental to the understanding of social interactions, including others' intentions and goals. In this work we deal with the extraction of joint attention events, and the use of such events for image descriptions. The work makes two novel contributions. First, our extraction algorithm is the first which identifies joint visual attention in single static images. It computes 3D gaze direction, identifies the gaze target by combining gaze direction with a 3D depth map computed for the image, and identifies the common gaze target. Second, we use a human study to demonstrate the sensitivity of humans to joint attention, suggesting that the detection of such a configuration in an image can be useful for understanding the image, including the goals of the agents and their joint activity, and therefore can contribute to image captioning and related tasks.
-
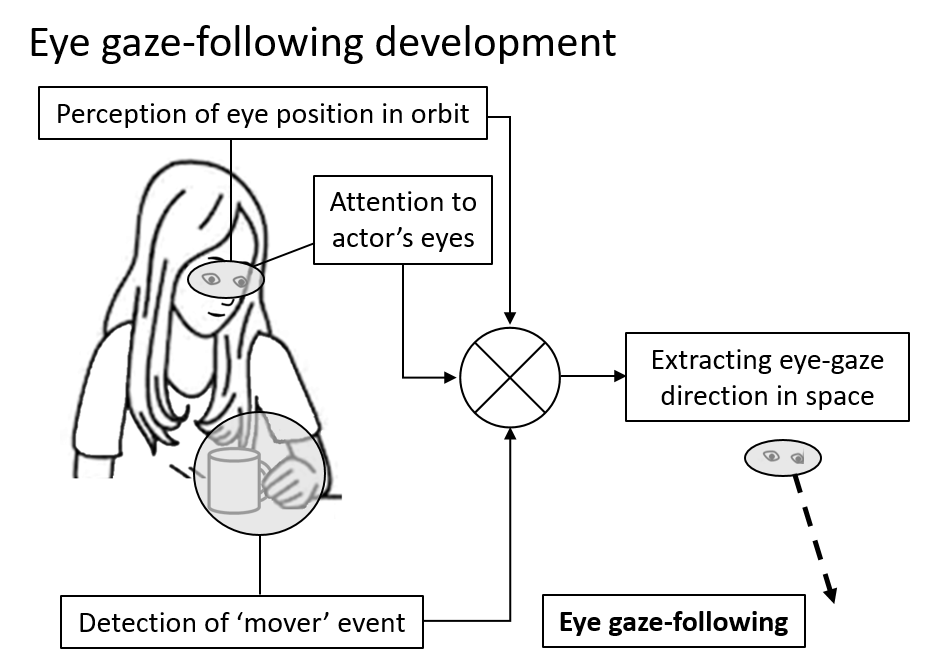 Gaze following requires early visual experience
Gaze following requires early visual experienceEarly in life, humans spontaneously learn to extract complex visual information without external guidance. Current vision models fail to replicate such learning, relying instead on extensive supervision. A classic example is gaze understanding, an early-learned skill useful for joint attention and social interaction. We studied gaze understanding in children who recovered from early-onset near-complete blindness through late cataract surgery. Following treatment, they acquired sufficient visual acuity for detailed pattern recognition, but they failed to develop automatic gaze following. Our computational modeling suggests that their learning is severely limited due to reduced availability of internal self-supervision mechanisms, which guide learning in normal development. The results have implications to understanding natural visual learning, potential rehabilitation, and obtaining unsupervised learning in vision models.

Computer Vision and Visual Intelligence
