


Learning to Perceive Coherent Objects
Nimrod Dorfman, Daniel Harari, Shimon Ullman

Abstract
Object segregation in a visual scene is a complex perceptual process that relies on the integration of multiple cues. The task is computationally challenging, and even the best performing models fall significantly short of human performance. Infants have initially a surprisingly impoverished set of segregation cues and their ability to perform object segregation in static images is severely limited. Major questions that arise are therefore how the rich set of useful cues is learned, and what initial capacities make this learning possible. Here we present a model that initially incorporates only two basic capacities known to exist at an early age: the grouping of image regions by common motion and the detection of motion discontinuities. The model then learns significant aspects of object segregation in static images in an entirely unsupervised manner by observing videos of objects in motion. Implications of the model to infant learning and to the future development of object segregation models are discussed.
Keywords: object segregation, cognitive development, developmental learning, unsupervised learning, visual cognition, ordinal depth, boundary features, learning from motion.
Early Development of Object Segregation

Initial object segregation by infants is based almost exclusively on dynamic cues, which are then used to learn static object segregation. We focus below on two main aspects of using visual motion for object segregation: grouping by common motion, and the use of motion discontinuities.
Common Motion
Infants use visual motion to group together adjacent regions that move together. These grouped image entities, discovered through motion, are also stored in memory and can subsequently be identified in static images. For example, if 4.5 months old see in a static image a region A next to a second region B, their expectations are shaped by their recent experience of seeing these regions in motion. If A and B moved together, infants will treat them as a unit and will be surprised if they move separately, but not if they saw A or B moving alone. The grouping of regions into a single unit depends on their common motion: if two regions differ in their image motion, even if they remain in contact, they are treated as separate objects. Retention in memory of the formed unit is limited in time, but grows gradually with age. This use of stored object representations for segregation is termed 'object-based segregation', and it can generalize with more experience to other similar objects ('class based' segmentation), provided that the differences are initially small.
Motion Discontinuities
In addition to region grouping based on common motion, infants are also sensitive from an early age (5 months or earlier) to dynamic cues created by the boundaries of moving objects.
Static Cues
In terms of static cues, at 3-5 months contiguous regions that are not separated by a visible gap tend to be grouped together, and are expected for example to move together rather than separately. At this age they show little or no evidence for using grouping principles based on uniformity of color, texture, and continuity of bounding contour in object perception. At 9 months the effect of such grouping cues is still weak. The learning of static cues is gradual, and appears to depend on familiarity with many objects.
Following extended learning, perceptual organization into distinct objects and their boundaries develops into a complex process that relies on a rich set of cues. In addition to image-based, or bottom-up properties, organization into objects depends on top-down cues, based on familiarity with specific objects and object classes. The different cues and their integration into a full segregation scheme are still a subject of active research in both human studies and computational modeling.
Goals of the Current Study
Infants are sensitive to motion cues for segregation, but lack sensitivity to most static cues for objects identity. It is therefore natural to ask how static segregation cues may be learned during development, guided by dynamic cues. We focus on two dynamic cues that are prominent in early infant perception. The first is common motion, guiding object-based segmentation. That is, infants naturally segregate adjacent image regions that share common motion, and can identify similar configurations in static images. One goal is therefore to model this learning of object-based segregation. Second, infants are sensitive to dynamic cues created by the boundaries of moving objects, and these are used by the model to learn useful static boundary cues. Although boundary ownership cues appear to play a major role in human object segregation, they are not usually used in computational models, in part because it is still unclear which features are useful for assigning boundary ownership. A possible outcome of a model for the unsupervised learning of boundary ownership features could be, therefore, the extraction and use of such features in future segmentation models and algorithms.
The Model
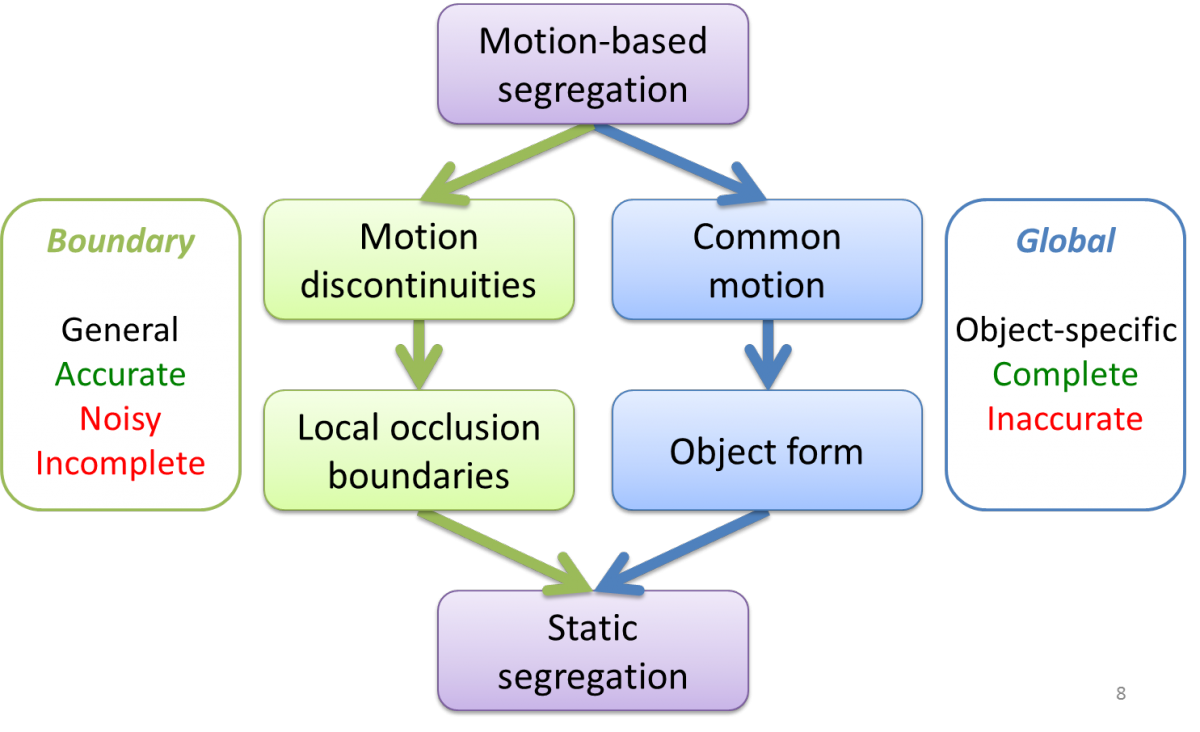
The current learning model has initially two 'innate' capacities for using visual motion to learn object segregation. The first is the capability to group together adjacent regions based on their common motion. A representation of the grouped shape is stored and can then be used for segregating similar shapes in novel static images. The second capacity is to extract motion discontinuities. These are used as teaching signals to extract image features located along object boundaries, together with a labeling of the figure/background sides, and subsequently use them to locate novel object boundaries and identify the figure direction in new static images.
Object-based Segregation
The goal of object-based segregation is to learn the appearance of a specific object, such as the doll, fruit, etc., in our movies, and then find the full extent of the object and separate it from its background under new settings. The part of the model that deals with object-based segregation is based on an object detection model used, with some variations, in computer vision schemes, termed 'star model'. For the purpose of object segregation, the model is augmented with a 'back projection' stage. The input to the object-based segregation is an image in a movie, together with the visual motion associated with the image. The motion computation divides the image into two components: a stationary one, and a set of one or more moving regions. One of the moving regions is selected for further processing. The object defined by the moving region is therefore represented by its center and a set of image descriptors, each one with its displacement from the object's center.
Learning Boundary Features
The accurate delineation of boundaries is important for interacting with objects, e.g. for grabbing, finding free space to place them, etc. This is obtained in the model by a second mechanism, which uses motion discontinuities to learn static cues for occluding boundaries. These motion discontinuities are used to guide the extraction of static boundary features and their figure-ground labeling. The motion signal is used to label the figure part (which is moving in the training images) and background part (which is stationary). The learned boundary features are then used to identify likely object boundaries in novel static images.


Discussion
The model demonstrates how static object segregation can be learned effectively guided by two motion based mechanisms known to be innate or early learned in infants' vision: grouping by common motion and sensitivity to motion discontinuities. These mechanisms are used by the model for two complementary goals: common motion is used for object-based segregation, and motion discontinuities are used for learning static occlusion cues. In agreement with infants learning, the learning of object-based segregation by the model is fast, with initial sensitivity to details of the object's internal texture. It identifies well the region of the object with reduced accuracy near the boundaries. Boundary cues require more prolonged learning, but they appear to generalize broadly to novel object images. The set of useful boundary features found by the model is large and varied, including a major contribution from extremal edges, which have played a limited role in modeling so far. The results of the study suggest a number of interesting directions for further research. In terms of infant studies, it will be of interest to test their capacity for object segregation based on extremal cues, which, to the best of our knowledge have not been tested so far. Another prediction that can be tested is whether object-based segregation by infants, which is sensitive to internal texture, will exhibit insensitivity to the object's boundary. Computationally, it will be interesting to compile a large set of useful boundary features that could be used by future segmentation algorithms. Finally, since scene segmentation in natural images is still a challenging open problem, it will be of interest to extend the current approach and examine whether following human development, by letting object segregation (including cues not considered in the current model) be guided and learned using dynamic cues, could lead to the emergence of models approaching human segregation capacities.

Paper
- Dorfman, N., Harari, D. and Ullman, S. (2013). Learning to Perceive Coherent Objects. Proceedings of The Annual Meeting of the Cognitive Science Society - CogSci, pp. 394-399. Winner of the 2013 Marr Prize. (Online, PDF)
Acknowledgements
The work was supported by European Research Council (ERC) Advanced Grant 'Digital Baby' (to S.U.).