


From Innate Biases to Complex Visual Concepts

Abstract
Early in development, infants learn to solve visual problems that are highly challenging for current computational methods. We present a model that deals with two fundamental problems in which the gap between computational difficulty and infant learning is particularly striking: learning to recognize hands and learning to recognize gaze direction. The model is shown a stream of natural videos, and learns without any supervision to detect human hands by appearance and by context, as well as direction of gaze, in complex natural scenes. The algorithm is guided by an empirically motivated innate mechanism – the detection of ‘mover’ events in dynamic images, which are the events of a moving image region causing a stationary region to move or change after contact. Mover events provide an internal teaching signal, which is shown to be more effective than alternative cues and sufficient for the efficient acquisition of hand and gaze representations. The implications go beyond the specific tasks, by showing how domain-specific ‘proto concepts’ can guide the system to acquire meaningful concepts, which are significant to the observer, but statistically inconspicuous in the sensory input.
Keywords: cognitive development, developmental learning, hand detection, unsupervised learning, visual cognition, direction of gaze, gaze following.
Detecting 'Mover' Events
 Example of mover detection results: detected mover events and tracked movers. Green, last outgoing pixels from cell of event; red, moving pixels of the tracked mover (restricted to a 30 x 30 region); blue rectangle, the 90 x 90 image patch extracted as a candidate hand.
Example of mover detection results: detected mover events and tracked movers. Green, last outgoing pixels from cell of event; red, moving pixels of the tracked mover (restricted to a 30 x 30 region); blue rectangle, the 90 x 90 image patch extracted as a candidate hand.Hands are frequently engaged in motion, and their motion could provide a useful cue for acquiring hand concepts. Infants are known to have mechanisms for detecting motion, separating moving regions from a stationary background, and tracking a moving region. However, our simulations showed that general motion cues on their own are unlikely to provide a sufficiently specific cue for hand learning: the extraction of moving regions from test video sequences can yield a low proportion of hand images, which provides only a weak support for extracting the class of hands. Infants are also sensitive, however, to specific types of motion, including launching, active (causing other objects to move), self-propelled, or passive. On the basis of these findings, we introduced in the model the detection of active motion, which we call “mover” event, defined as the event of a moving image region causing a stationary region to move or change after contact. Mover detection is simple and primitive, based directly on image motion without requiring object detection or region segmentation.


Learning to Detect Hands by Appearance and Context

Detection is initially limited to specific hand configurations extracted as movers, typically engaged in object grasping. Detection capabilities rapidly increase during the learning process based on two mechanisms: tracking and body context. Developmental evidence indicates that young infants already have these capacities at an early age. Because hands are detected on the basis of either appearance or body context, we found that the two detection methods cooperate to extend the range of appearances and poses used by the algorithm. The context-based detection successfully recognizes hands with novel appearances, provided that the pose is already known (“pose” here is the configuration of context features, on the shoulders, arms, etc.). The newly learned appearances lead in turn to the learning of additional poses. The results show that appearance-based and context-based recognition guide each other to boost recognition performance.
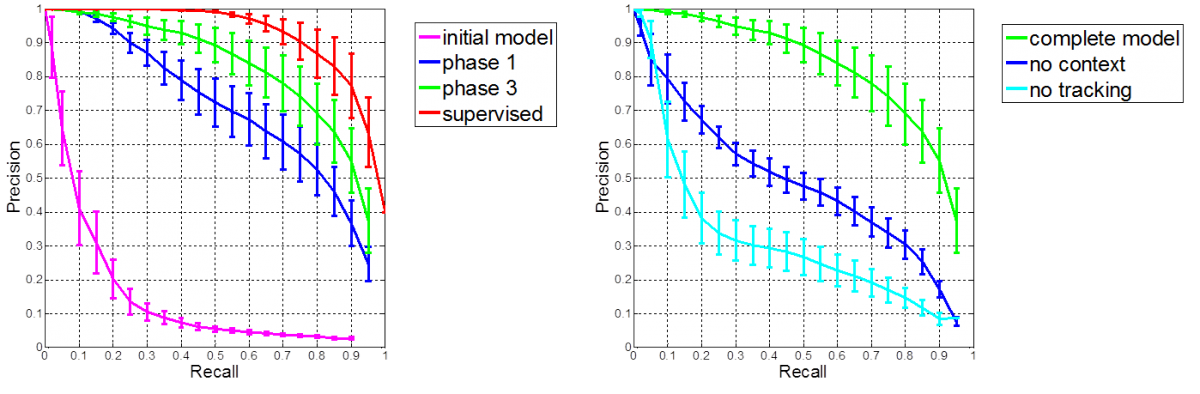
Learning to Detect Direction of Gaze
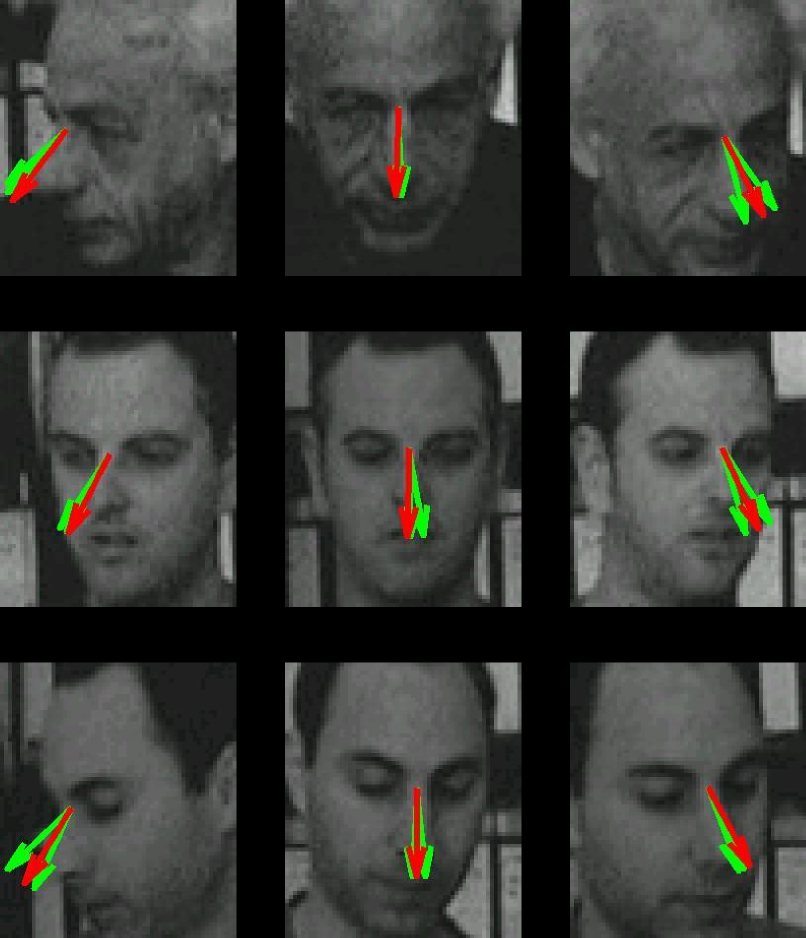
Infants’ looking is attracted by other people’s hands engaged in object manipulation, and they often shift their gaze from face to a manipulating hand. People often look at objects they manipulate, especially slightly before and during initial object contact. Our algorithm therefore uses mover events as an internal teaching signal for learning direction of gaze. It detects presumed object contacts by detecting mover events, extracts a face image at the onset of each mover event, and learns, by standard classification techniques, to associate the face image with the 2D direction to the contact event. Consistent with developmental evidence, we assume that initial face detection is present before gaze learning, and locate the face with an available face detector. The resulting classifier estimates gaze direction in novel images of new persons with accuracy approaching adult human performance under similar conditions.

Related Publications
- Ullman, S., Harari, D. and Dorfman, N. (2012). From simple innate biases to complex visual concepts. Proceedings of the National Academy of Sciences - PNAS 109(44): 18215-18220. (Abstract, PDF)
- Yuille, A. L. and Bulthoff, H. H. (2012). Action as an innate bias for visual learning [Commentary]. Proceedings of the National Academy of Sciences - PNAS 109(44): 17736–17737. (Extract, PDF)
Press
- Halper J.(Fall 2012). Seeing Like a Baby. Weizmann Wonder Wander. Retrieved from: http://wis-wander.weizmann.ac.il/ (Hebrew version)
Blog
- Halper J. (2012, November 18). A Computer That Learns to See Like a Baby. The Weizmann Wave. Blog at: http://scienceblogs.com/weizmann/
Acknowledgements
The work was supported by European Research Council (ERC) Advanced Grant 'Digital Baby' (to S.U.).