
-
 Atoms of recognition
Atoms of recognitionThis project aims to explore the recognition capacity of tiny image patches of objects, object parts and object interactions, we call MIRC - MInimal Recognizable Configurations. These tiny images are minimal in the sense that any cropped or down-scaled sub-images of them, are no longer recognizable for human observers. The project addresses both psychophysical aspects of this capacity, as well as computational recognition mechanisms to support such a capacity.
-
 What takes the brain so long: Object recognition at the level of minimal images develops for up to seconds of presentation time
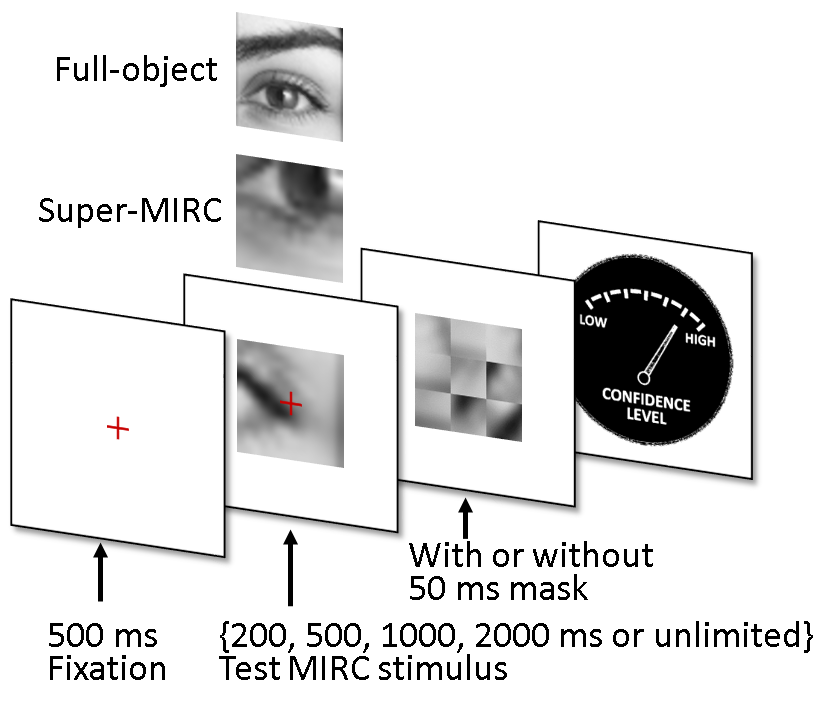
What takes the brain so long: Object recognition at the level of minimal images develops for up to seconds of presentation timeRich empirical evidence has shown that visual object recognition in the brain is fast and effortless, with relevant brain signals reported to start as early as 80 ms. Here we study the time trajectory of the recognition process at the level of minimal recognizable images (termed MIRC). Subjects were assigned to one of nine exposure conditions: 50 up to 2000 ms with or without masking, and unlimited time. The subjects were not limited in time to respond after presentation. The results show that in the masked conditions, recognition rates develop gradually over an extended period, e.g. average of 18% for 200 ms exposure and 45% for 500 ms, increasing significantly with longer exposure even above 2 secs. When presented for unlimited time (until response), MIRC recognition rates were equivalent to the rates of full-object images presented for 50 ms followed by masking. What takes the brain so long to recognize such images? We discuss why processes involving eye-movements, perceptual decision-making and pattern completion are unlikely explanations. Alternatively, we hypothesize that MIRC recognition requires an extended top-down process complementing the feed-forward phase.
-
 Scene understanding
Scene understandingVisual scene understanding is a fundamental cognitive ability, which involves integration of multiple processes at different levels, including depth and spatial relations, object detection and recognition of actions and interactions.
Trying to answer a question such as, "What happens in this image?", a child is able to answer something like, "A boy was climbing on a tree trunk to help a small kitten down, while two other children and a dog were watching."
We are interested in understanding the computational mechanisms underlying this remarkable cognitive ability in humans, and aim to develop computational models based on these mechanisms towards artificial human-level scene understanding. -
 Variable resolution (foveation)
Variable resolution (foveation)The ability to recognize and segment-out small objects and object parts in a cluttered background is challenging for current visual models, including deep neural networks. In contrast, humans master this ability, once fixated at the target object. In this project we explore a variable resolution model for object recognition, inspired by the human retinal variable resolution system. Given restricted computational resources, the model acquires visual information at a high resolution around the fixation point, on the expense of lower resolution at the periphery. We evaluate the efficiency of the model by comparing its performance with an alternative constant resolution model. We test the model's ability to 'fixate' on the target by applying the model iteratively to a set of test images, and compare the results with human fixation trajectory given the same image stimuli.
-
 Emergent Neural Network Mechanisms for Generalization to Objects in Novel Orientations
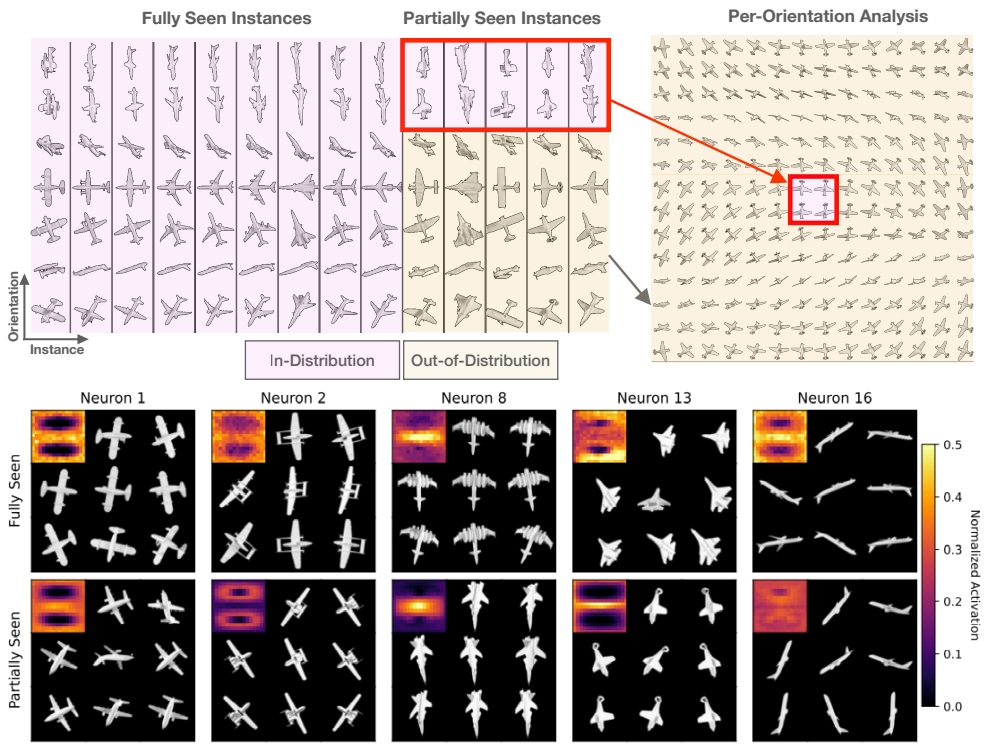
Emergent Neural Network Mechanisms for Generalization to Objects in Novel OrientationsThe capability of Deep Neural Networks (DNNs) to recognize objects in orientations outside the training data distribution is not well understood. We investigate the limitations of DNNs’ generalization capacities by systematically inspecting DNNs' patterns of success and failure across out-of-distribution (OoD) orientations. We present evidence that DNNs (across architecture types, including convolutional neural networks and transformers) are capable of generalizing to objects in novel orientations, and we describe their generalization behaviors. Specifically, generalization strengthens when training the DNN with an increasing number of familiar objects, but only in orientations that involve 2D rotations of familiar orientations. We also hypothesize how this generalization behavior emerges from internal neural mechanisms – that neurons tuned to common features between familiar and unfamiliar objects enable out of distribution generalization – and present supporting data for this theory. The reproducibility of our findings across model architectures, as well as analogous prior studies on the brain, suggests that these orientation generalization behaviors, as well as the neural mechanisms that drive them, may be a feature of neural networks in general.
-
 Adaptive parts model project
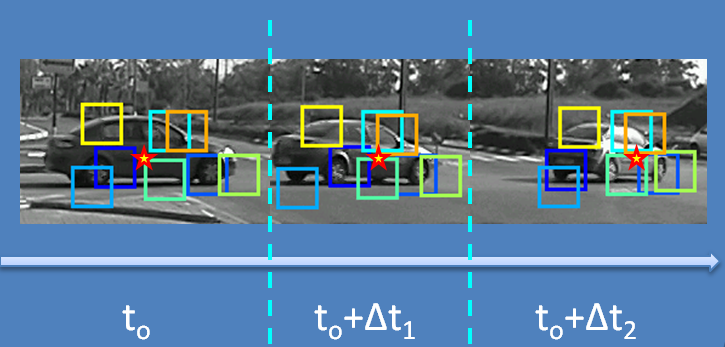
Adaptive parts model projectThis project aims to explore the adaptation of a visual recognition system in a dynamically changing environment. Given an initial model of an object category from a certain viewing direction, we suggest a mechanism to extend recognition capabilities to new viewing directions, by observing unlabeled natural video streams.

Computer Vision and Visual Intelligence
