


Atoms of recognition in human and computer vision
Shimon Ullman, Liav Assif, Ethan Fetaya, Daniel Harari

Overview
Discovering the visual features and representations used by the brain to recognize objects is a central problem in the study of vision. The successes of recent computational models of visual recognition naturally raise the question: do computer systems and the human brain use similar or different computations? We show by combining a novel method ('minimal images') and simulations that the human recognition system uses features and learning processes not used by current models, which are critical for recognition. The study uses a 'phase transition' phenomenon in minimal images, where minor changes to the image make a drastic effect on its recognition. The results show fundamental limitations of current approaches and suggest directions to produce more realistic and better performing models.
Discovering MIRCs
A minimal recognizable configuration (MIRC) is defined as an image patch that can be reliably recognized by human observers, and which is minimal in the sense that further reduction by either size or resolution makes the patch unrecognizable. To discover MIRCs, we conducted a large-scale psychophysical experiment for classification. We started from 10 greyscale images, each showing an object from a different class, and tested a large hierarchy of patches at different positions and decreasing size and resolution.

Each patch in this hierarchy has 5 descendants, obtained by either cropping or reduced resolution. If an image patch was recognizable, we continued to test its descendants by additional observers. A recognizable patch in this hierarchy is identified as a MIRC if none of its 5 descendants reach a recognition criterion (50% recognition, results are insensitive to criterion).
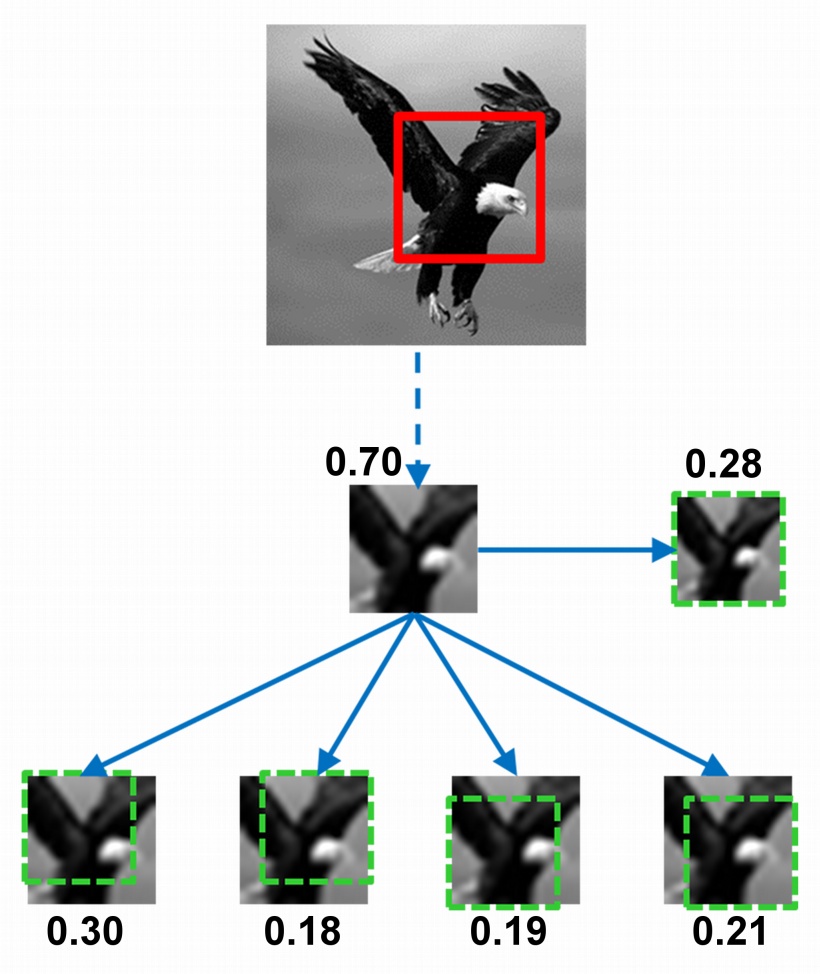
Each human subject viewed a single patch from each image with unlimited viewing time, and was not tested again. Testing was conducted online using the Amazon Mechanical Turk with about 14,000 subjects, viewing 3,553 different patches. The size of the patches was measured in image samples, which is the number of samples required to represent the image without redundancy (twice the image frequency cutoff). For presentation to subjects, all patches were scaled to 100x100 pixels by standard interpolation; this increases the size of the presented image smoothly without adding or losing information.

The transition in recognition rate from a MIRC image to a non-recognizable descendant (termed 'sub-MIRC') is typically sharp: a surprisingly small change at the MIRC level can make it unrecognizable. The drop in recognition rate was quantified by measuring a 'recognition gradient', defined as the maximal difference in recognition rate between the MIRC and its 5 descendants; average gradient was 0.57. This indicates that much of the drop from full to no recognition occurs for a small change at the MIRC level. These small changes at the MIRC level disrupt visual features that the recognition system is sensitive to, which are present in the MIRCs but not the sub-MIRCs. Crucially, the role of these features is revealed uniquely at the MIRC level, since in the full-object image, information is more redundant and a similar loss of features will have a small effect.

Testing MIRCs with computational models of vision
We have tested computationally whether current models of human and computer vision extract and use similar visual features, along with their ability to recognize minimal images at a human level, by comparing recognition rates of models at the MIRC and sub-MIRC levels. The models in our testing included HMAX, a high performing biological model of the primate ventral stream, along with 4 state-of-the-art computer vision models, Deformable Part Model (DPM), support vector machines (SVM) applied to histograms of gradients (HOG), extended Bag-of-Words and deep convolutional networks (DCNN), all among the top-performing schemes in standard evaluations.
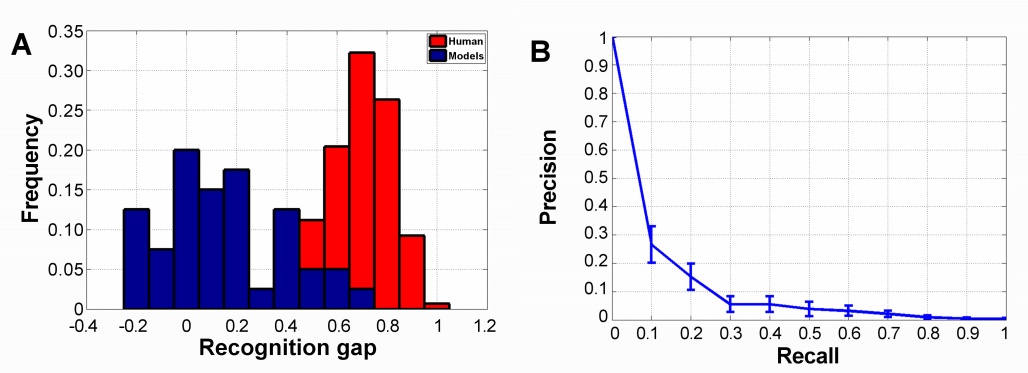
We found that the computational models did not reproduce the transition in recognition rates when applied to MIRCs and to sub-MIRCs. As can be seen in the figure below (A), the gap in recognition rate for the models is much lower compared to the gap for humans. Our simulations showed that current models cannot explain the sensitivity to precise feature configurations, and more generally, do not learn to recognize minimal images at a human level.
Discussion
The results indicate that the human visuals system uses features and processes, which current models do not. As a result, humans are better at recognizing minimal images, and they exhibit a sharp drop in recognition at the MIRC level, which is not replicated in models. The sharp drop at the MIRC level also suggests that different human observers share similar visual representations, since the transitions occur for the same images, regardless of individual visual experience. An interesting open question is whether the additional features and processes are employed in the visual system as a part of the cortical feed-forward process, or by a top-down process, which is currently missing from the purely feed-forward computational models. We hypothesize based on initial computational modeling that top-down processes are likely to be involved. The reason is that detailed interpretation appears to require features and interrelations, which are relatively complex and are class-specific, in the sense that their presence depends on a specific class and location. This naturally divides the recognition process into two main stages: The first leads to the initial activation of class candidates, which is incomplete and with limited accuracy. The activated representations then trigger the application of classspecific interpretation and validation processes, which recover richer and more accurate interpretation of the visible scene. A further study of the extraction and use of such features by the brain, combining physiological recordings and modeling, will extend our understanding of visual recognition and improve the capacity of computational models to deal with recognition and detailed image interpretation.
Related Publications
-
Ullman, S., Assif, L., Fetaya, E., Harari, D. (2016). Atoms of recognition in human and computer vision. Proceedings of the National Academy of Sciences - PNAS, 113(10): 2744-2749 (Abstract,PDF)
- Ben-Yosef, G., Assif, L., Harari, D., Ullman, S. (2015). A model for full local image interpretation. The Annual Conference of the Cognitive Science Society - CogSci (Abstract,PDF)
Press
- Hsu, J. Digital Baby Project's Aim: Computers That See Like Humans, IEEE Spectrum. Retrieved from: http://spectrum.ieee.org/ (2016)
- Brueck, H. Why You're Still Smarter Than A Computer, Fortune. Retrieved from: http://fortune.com/ (2016)
- Gray, R. AI computers are no match for human eyes when it comes to recognizing small details, Daily Mail Online. Retrieved from: http://www.dailymail.co.uk/ (2016)
- Yirka, B. Study suggests humans and computers use different processes to identify objects visually, Tech Xplore. Retrieved from: http://techxplore.com/ (2016)
- Less than Meets the Eye. How do computers - or our brains - recognize images?, Weizmann Wonder Wander. Retrieved from: http://wis-wander.weizmann.ac.il (Hebrew version) (2016)
Blogs
- O'Grady, C. Tiny, blurry pictures find the limits of computer image recognition, Ars Technica. Blog (2016)
- How Differently Do Humans and Computers Visually Identify Objects?, Tech The Day. Blog (2016)
- The Weizmann Wave. Blog (2016)
- Less than Meets the Eye, Robo Daily. Blog (2016)
Acknowledgements
The work was supported by European Research Council (ERC) Advanced Grant 'Digital Baby' (to S.U.), and by the Center for Brains, Minds and Machines (CBMM), funded by National Science Foundation (NSF) Science and Technology Centers Award CCF-1231216.