


ERC research grant to Prof. Shimon Ullman
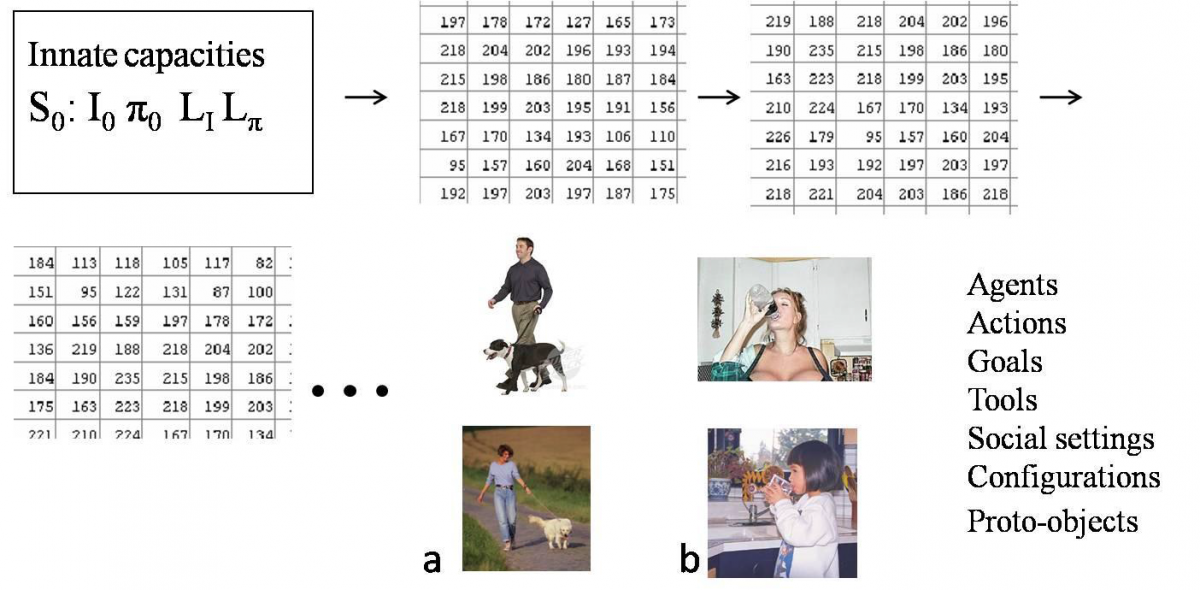
Overview
The goal of this research effort is to construct large-scale computational modeling of how knowledge of the world emerges from the combination of innate mechanisms and visual experience. The ultimate goal is a ‘digital baby’ model which, through perception and interaction with the world, develops on its own representations of complex concepts that allow it to understand the world around it, in terms of objects, object categories, events, agents, actions, goals, social interactions, and the like.
This ‘emergence of understanding’ is a major open challenge in the study of cognition and the brain. Vision plays a major (though not exclusive) part in this task. Current computational theories dealing with the acquisition of knowledge about the world through visual perception still cannot adequately cope with this major challenge. These theories have made progress over the past decade in dealing e.g. with object categorization, but cannot deal effectively with natural cognitive concepts, which depend not only on statistical regularities in the sensory input, but also on their significance and meaning to the observer. As a result, current methods are inherently limited in their capacity to acquire in a meaningful way cognitive concepts related to agents in the world, their goals and actions, social interactions and others.
This research suggests a new approach to the problem based on two key concepts: ‘computational Nativism’ and ‘embedded inference’. The goal of the study is to show how processes based on the proposed concepts lead to the learning of the basic notions themselves, (e.g., of an object, an action or a tool), and many specific examples of particular objects, categories, actions, tools, etc. The modeling will use available cognitive and neuroscience data and it will develop by computational analysis and simulations a functioning and testable model for the acquisition of complex concepts from experience.
The research program will proceed by studying and modeling (i) a set of innate capacities, which exist in the learning system and make the emergence of understanding possible, (ii) the learning mechanisms (two main ones), and (iii) how the two work together (in the so-called ‘embedded inference’ loop). The model will receive extensive visual (and some non-visual) training, and it will develop on its own, without further intervention, useful representations of objects, actions and events in the world.
We dub the model system a ‘digital baby’ because it faces similar problems to an infant trying to use her/his experience to understand the world. However, the goal is not to directly model the actual processes of cognitive development. The wealth of informative empirical evidence from developmental studies will be used to provide guidance and constraints, but the main focus will be on underlying computational issues: what innate mechanism are necessary or highly beneficial in facilitating the learning process, and how can different abstract and concrete notions be learned from experience.
Fundamental nature of current limitations
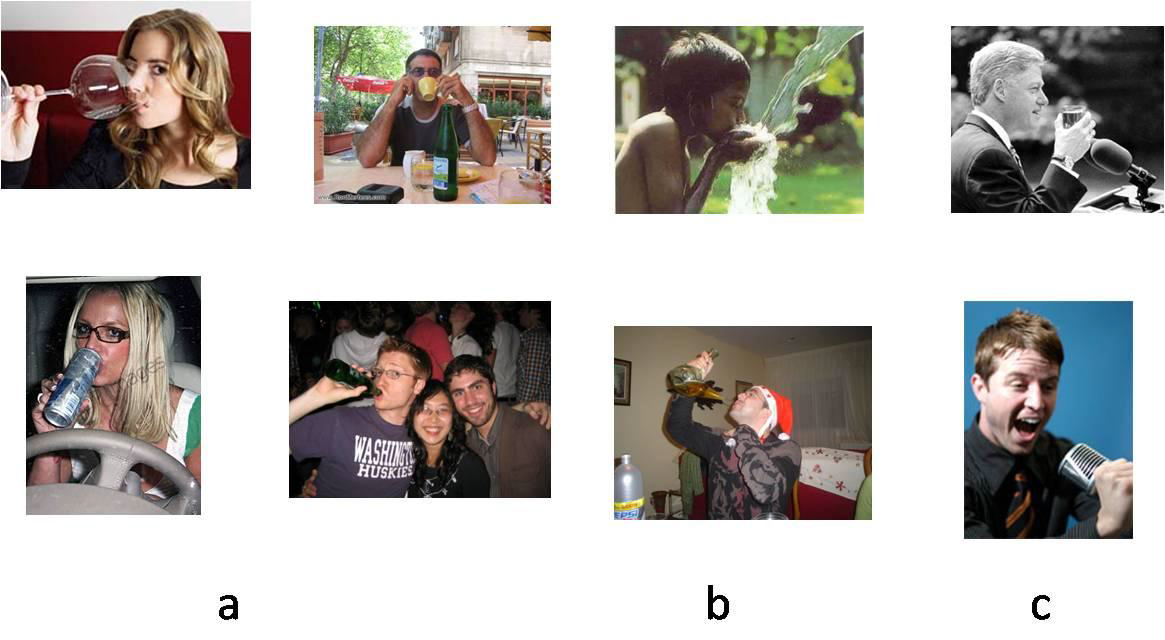
One basic limitation of most current approaches in the domains above is that they are too ‘visual’, and a second limitation is that they are too ‘empiricist’. In learning visual categorization, most models represent visual classes as repeated arrangements of shared visual features. Therefore, the discovery of visual categories has been based on the extraction of repeating visual patterns and the detection of statistical regularities in the sensory input. In contrast, humans can learn and use categories that are no longer ‘visual classes’ in this sense, but are more semantic in the sense that they require instead a more abstract understanding of non-visual concepts such as goal, tool, agent, and the like.
The above figure illustrates an example we have already studied in some detail, dealing with the notion of ‘drinking’, where the limitation of current approaches become apparent. Figure (a) shows only a small number of examples, but they already illustrate the wide variability in possible ‘drinking’ examples. Figure (b) shows examples of less standard drinking; they are different as visual objects from typical drinking, but carry a similar meaning, which needs to be captured by the learning scheme. Figure (c) shows examples of configurations similar to drinking, but they differ from ‘drinking’ in subtle ways. For example, ‘toasting’ is visually very close to ‘drinking’, but preliminary psychophysical testing has shown that observers, even when un-instructed, spontaneously notice the difference between the two actions. Our computational experimentation with this problem has shown that applying three leading visual categorization methods to ‘drinking’ examples fail to yield adequate categorization results. This is perhaps not surprising, because ‘drinking’ is not fundamentally a visual class: examples can vary widely in their appearance; their common aspect is defined by the goal of bringing liquid to the mouth, rather than by a repeating visual appearance. The difficulty in acquiring such categories is related to the bias of current approaches to be too ‘empiricist’ in nature, with emphasis on learning from experience and usually only a little on contributions from innate structures and biases. To make correct semantic categorizations, the system needs to focus on aspects of the input that are functionally important but can be non-salient and not highly repetitive. We will see in the next section how the incorporation of innate domain-specific proto-concepts and capacities can guide the system through its subsequent acquisition of novel concepts.
Domains of study

Actions, agents, goals and tools
Understanding an action is more than naming it, or identifying instances in which the action takes place. Additional aspects of understanding include for example the identification of the participants playing a role in the action – the agent, recipient, tool, and often relevant body parts. An objective of the model is therefore to develop on its own this sort of understanding. The capacity to identify the action components will be evaluated at different learning stages by testing the ability of the model, when learning a new action, to ‘point back’ in the image to the agent, tool, recipient, and relevant body parts. As all examples, this capacity will emerge and develop on its own based on some simple innate proto-concepts and accumulated experience. Other aspects of the emerged understanding, which will be included in the model and tested throughout learning, include retrieving from memory other tools that may be used for the same action, additional examples of the same action, the goal-state of the action, and predicting likely continuations in time of the observed configuration.
Social settings: multi-agent interactions
Humans can quickly infer complex aspects of interactions between agents, such as ‘arguing’ or ‘hug’. Recent preliminary studies found that complex interactions can be identified from brief presentations as quickly and efficiently as the identification of basic objects. Developmentally, studies show that infants differentiate aspects of social interactions based on visual information. The recovery of socially related information from visual cues is a broad domain that covers different sub-areas. Because this is a broad and difficult domain, we will start with a small selected set of objectives, of some social settings between agents, which can be recovered quickly from a single static image. Two settings we will include are images of disagreement, or confrontation, and image portraying ‘hug’. The ‘hug’ situation lies somewhere between an action and a social setting, but it has social aspects in the sense that it involves an interaction between agents, and it is associated with a certain social attitude.
Meaningful configurations
Different objects can be arranged in configurations that are meaningful to the observer. For example, a collection of objects arranged either as a table set for dinner or a table after dinner. Meaningful arrangements form a level of organization above the single object level, and are therefore difficult to learn and interpret. In meaningful configurations, the participating objects can differ and there can be large variability in the arrangement that preserved the meaning conveyed to the observer. We will include in the training set a number of indoors and outdoors configurations. By developing methods to recognize such configurations, we will address basic issues related to ‘compositionality’ and how the meaning of a configuration is related to the component objects and their relationships.
Proto-objects and "affordances"
We naturally understand the meaning and function of entities ‘above’ the object level, such as meaningful object configurations, but also of entities ‘below’ the object level, such as a pocket, a crease, a piece of a pavement, etc. These are not stand-alone objects and are not visually salient. Humans still notice, represent and recognize them based on their significance, potential use in actions, or possible effects on a planned action (related to Gibson’s notion of their ‘affordances’). In our past work on recognition we found that, because of their semantic rather than visual salience, current methods fail to cope with such entities. We will include two objectives in this domain. One is the discovery of proto-objects that have functional role, such as a handle or a zipper: we will inquire what is required to make them be extracted and represented. Second, we will select several affordances, such as rough, smooth, hard, soft; these will be studied in the collaboration on multi-sensory cues.
Examples of specific problems
A number of related concepts that the ‘digital baby’ will acquire revolve around people, their body parts, and their role in performing actions:
Faces
Study the development of selective responses to faces, and the continued evolution of the representation of faces and face parts.
Hands
Study the development of the capacity to detect and represent hands, their shape and interactions with objects.
Grasping types
Learning about subtle but meaningful distinctions between different types of grasping. This is an example of subtle classification governed by semantic rather than appearance criteria.
Animals
Include in the training data scenarios containing pets, such as dogs and cats, and their interaction with humans. We will study the development of the representations of moving, animate agents.
Actions
Understanding what people are doing by watching their behavior as a major component of the ‘emergence of understanding’.
The development of ‘Mirroring’ association
The so-called ‘mirroring system’ has been proposed to play an important role in understanding the activities of other agents. This is a broad domain, but within it, we will study how to form associations between visual and non-visual representation of body parts.
Tools
Basic proto-concepts we plan to study for learning about tools are related to active and passive motion and to learning about hands. Tools are correlated with passively moving regions, set into motion by hands. We will study the use of target body part as a possible cue for tools types.
Direction of Gaze
At about four month of age, infants reliably discriminate between direct and averted gaze, and a few months later they show tendency to shift their attention in the direction of another’s gaze. In terms of initial concepts, we will study and compare two possibilities for the development of the ability to recognize eyes and gaze directions – direct and indirect ones. The direct assumes the existence of some proto-concepts associated directly with visual features used for the task. The indirect approach is that features for direction of looking are not by themselves wired into the system, but derived during learning, guided indirectly be other cues.
Object segregation
Object segregation in a visual scene is a complex perceptual process that relies on the integration of multiple cues. The task is computationally challenging, and even the best performing models fall significantly short of human performance. Infants have initially a surprisingly impoverished set of segregation cues and their ability to perform object segregation in static images is severely limited. Major questions that arise are therefore how the rich set of useful cues is learned, and what initial capacities make this learning possible.
Containment
This recognition capability of containment, where one object is perceived as contained within another object, is aparently not innate, however it is develping rapidly in young infants during the first 6 months of their lives. We investigate different aspects of this recognition capability, including the learning of coherent objects' segregation, special visual cues of containers and the perception of containment events, both in static and dynamic scenes.
Multi-agents interactions
We will include initially two types of interactions between agents: ‘hug’ and ‘disagreement’. We will explore in particular what are the main cues, in the body configuration, hands, gaze direction etc. that can be used in this task.
Related Publications
-
Papers based on work done under the ERC Digital Baby are still coming out:Holzinger, Y. Ullman, S.Behrmann, M. Avidan, G. Minimal Recognizable Configurations (MIRCs) elicit category-selective responses in higher-order visual cortex. Submitted.
-
Ben-Yosef, G, Kreiman, G., Ullman, S. Spatiotemporal interpretation features in recognition of dynamic images. Submitted.
-
-
Ullman, S. Using neuroscience to develop artificial intelligence. Science, 363 (6428), 692-693, 2019.
-
Ullman, S, Dorfman, N, Harari, D. (2019) A model for discovering ‘containment’ relations., Cognition, 183: 67-81
-
Ben-Yosef, G. and Ullman, S. (2018). Image interpretation above and below the object level. Roy. Soc. Interface Focus 6;8(4)
-
Ben-Yosef G, Assif L, Ullman S. (2017). Full interpretation of minimal images Cognition. 171, 65-84.
-
Ben-Yosef, G. and Ullman, S. (2017). Structured learning and detailed interpretation of minimal object images. ICCV Workshop on Mutual Benefits of Cognitive and Computer Vision.
-
Ben-Yosef, G. Yachin, A., Shimon Ullman, S. (2017). A model for interpreting social interactions in local image regions. 2017. AAAI Spring Symposium Series, Science of Intelligence, Palo Alto, CA.
- Ullman, S., Assif, L., Fetaya, E., Harari, D. (2016). Atoms of recognition in human and computer vision. Proceedings of the National Academy of Sciences - PNAS (in press) (Abstract,PDF)
-
Rosenfeld, A. Ullman, S. (2016). Hand-Object Interaction and Precise Localization in Transitive Action Recognition. Proceedings of Computer and Robot Vision (CRV) 2016.
-
Lifshitz, I., Ethan Fetaya, E., Ullman. S. (2016). Human Pose Estimation using Deep Consensus Voting. Proceedings of ECCV 2016
-
Harari, D., Gao, T., Kanwisher, N., Tenenbaum, J., & Ullman, S. (2016). Measuring and modeling the perception of natural and unconstrained gaze in humans and machines. CBMM Memo No. 059, arXiv preprint arXiv:1611.09819. (PDF)
- Ben-Yosef, G., Assif, L., Harari, D., Ullman, S. (2015). A model for full local image interpretation. The Annual Conference of the Cognitive Science Society - CogSci (Abstract,PDF)
-
Fetaya, E., Shamir, O. Ullman, S. (2015). Graph Approximation and Clustering on a Budget. Proceedings of the 18th International Conference on Artificial Intelligence and Statistics (AISTATS) 2015, San Diego, volume 38.
-
Fetaya, E. Ullman, S. (2015). Learning Local Invariant Mahalanobis Distances. Proceedings of ICML 2015.
-
Berzak, Y. Barbu, A. Harari, D. Katz, B. Ullman, S. (2015). Do You See What I Mean? Visual Resolution of Linguistic. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 1477–1487,
- De la Rosa, S., Choudhery, R.N., Curio, C., Ullman, S., Assif, L., Bulthoff, H.H. (2014). Visual categorization of social interactions. Visual Cognition, 22(9-10): 1233–1271. (Abstract, PDF)
-
Markov NT, Vezoli J, Chameau P, Falchier A, Quilodran R, Huissoud C, Lamy C, Misery P, Giroud P, Ullman S, Barone P, Dehay C, Knoblauch K, Kennedy H. (2014). The anatomy of hierarchy: Feedforward and feedback pathways in macaque visual cortex. i
-
Gao, T., Harari, D., Tenenbaum, J., & Ullman, S. (2014). When computer vision gazes at cognition. CBMM Memo No. 025, arXiv preprint arXiv:1412.2672. (http://arxiv.org/pdf/1412.2672v1)
- Poggio, T., Ullman, S. (2013). Vision: are models of object recognition catching up with the brain? Annals of the New York Academy of Sciences, 1305: 72–82. (Abstract, PDF)
- Dorfman, N., Harari, D., Ullman, S. (2013). Learning to Perceive Coherent Objects. Proceedings of The Annual Meeting of the Cognitive Science Society - CogSci, pp. 394-399. (Abstract, PDF, Winner of the 2013 Marr prize)
- Harari, D., Ullman, S. (2013). Extending recognition in a changing environment. Proceedings of the International Conference on Computer Vision Theory and Applications - VISAPP, 1: 632-640. (Abstract, PDF)
- Ullman, S., Harari, D., Dorfman, N. (2012). From simple innate biases to complex visual concepts. Proceedings of the National Academy of Sciences - PNAS 109(44): 18215-18220. (Abstract, PDF)
-
With commentary: Yuille, A.L & Bülthoff, H.H. (2012). Action as an innate bias for visual learning. PNAS, 109(44), 17736–17737
-
Karlinsky, L. & Ullman, S. (2012). Using linking features in learning non-parametric part models.
In: Springer-Verlag Berlin Heidelberg, A. Fitzgibbon et al. (Eds.): ECCV 2012, Part III, 327–340. -
Owaki, T, Vidal-Naquet, M, Sato, T, Chateau, H, Ullman, S, Tanifuji, M. (2012). Diversity of visual features represented in a face selective sub-region of macaque anterior inferior temporal cortex. Society for Neuroscience Abstract, New Orleans.